Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Video with Independent Prediction
Paper and Code
Jan 17, 2019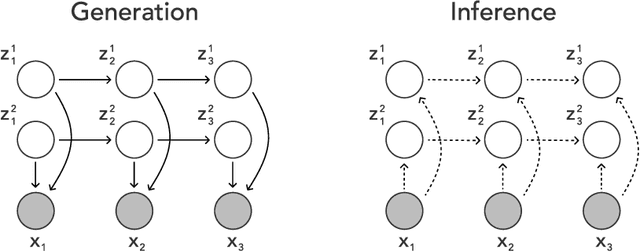

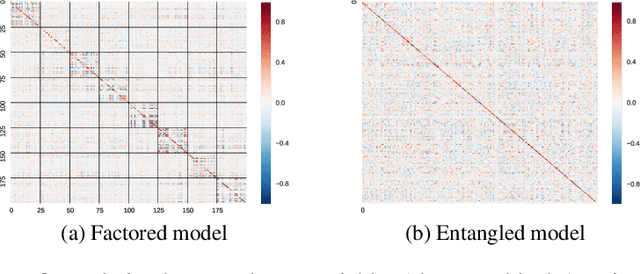
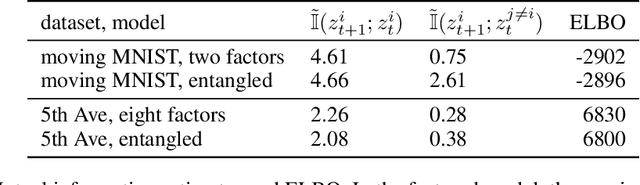
We propose an unsupervised variational model for disentangling video into independent factors, i.e. each factor's future can be predicted from its past without considering the others. We show that our approach often learns factors which are interpretable as objects in a scene.
* Presented at the Learning Disentangled Representations: from
Perception to Control workshop at NIPS 2017
View paper on