 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeX: Bit-Flexible Encoding for Streaming-based FPGA Acceleration of DNNs
Paper and Code
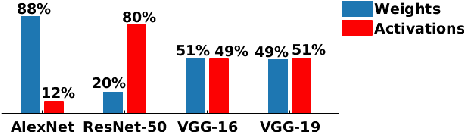
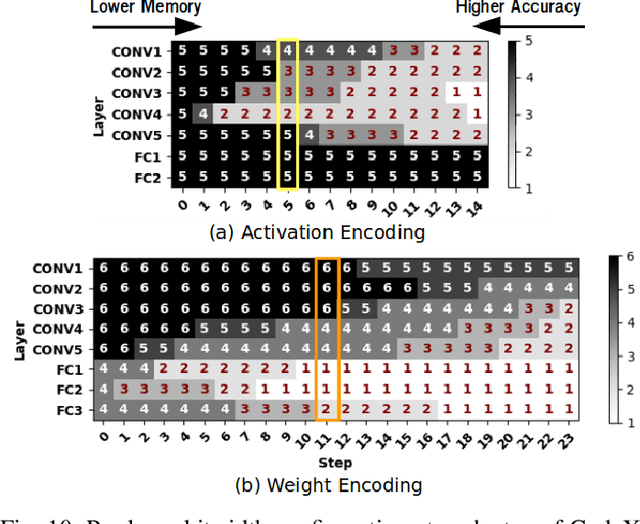
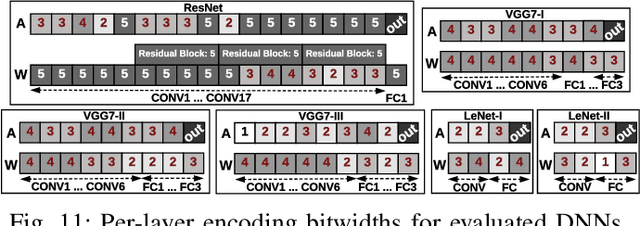
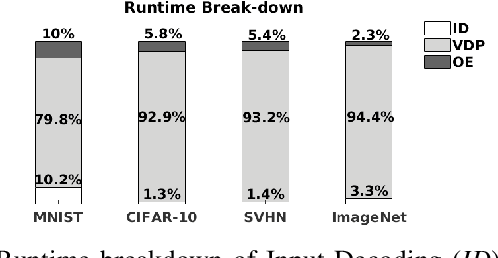
This paper proposes CodeX, an end-to-end framework that facilitates encoding, bitwidth customization, fine-tuning, and implementation of neural networks on FPGA platforms. CodeX incorporates nonlinear encoding to the computation flow of neural networks to save memory. The encoded features demand significantly lower storage compared to the raw full-precision activation values; therefore, the execution flow of CodeX hardware engine is completely performed within the FPGA using on-chip streaming buffers with no access to the off-chip DRAM. We further propose a fully-automated algorithm inspired by reinforcement learning which determines the customized encoding bitwidth across network layers. CodeX full-stack framework comprises of a compiler which takes a high-level Python description of an arbitrary neural network architecture. The compiler then instantiates the corresponding elements from CodeX Hardware library for FPGA implementation. Proof-of-concept evaluations on MNIST, SVHN, and CIFAR-10 datasets demonstrate an average of 4.65x throughput improvement compared to stand-alone weight encoding. We further compare CodeX with six existing full-precision DNN accelerators on ImageNet, showing an average of 3.6x and 2.54x improvement in throughput and performance-per-watt, respectively.