 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Learning in reproducing kernel Hilbert space
Paper and Code
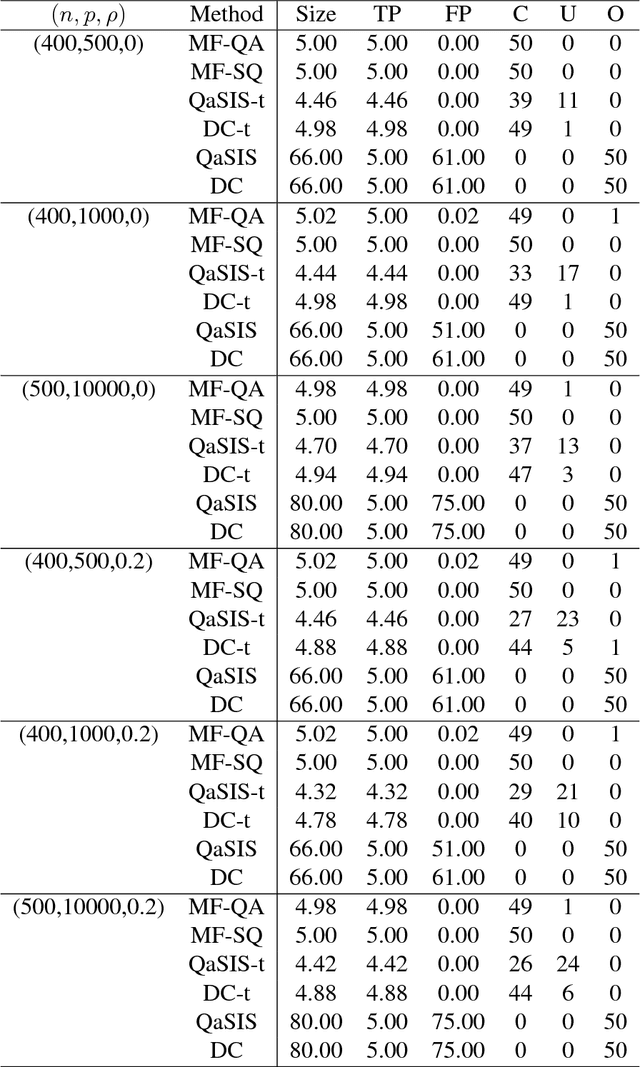
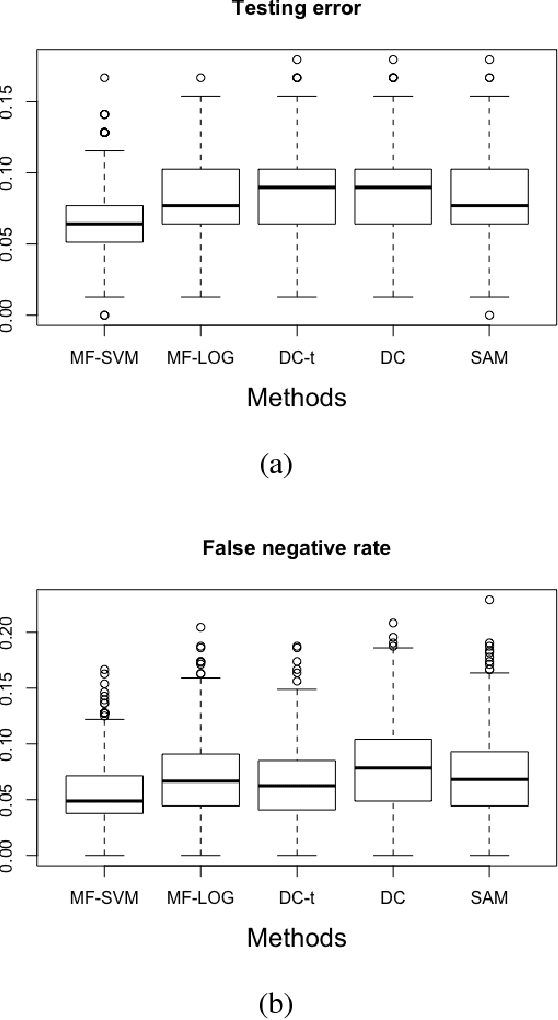
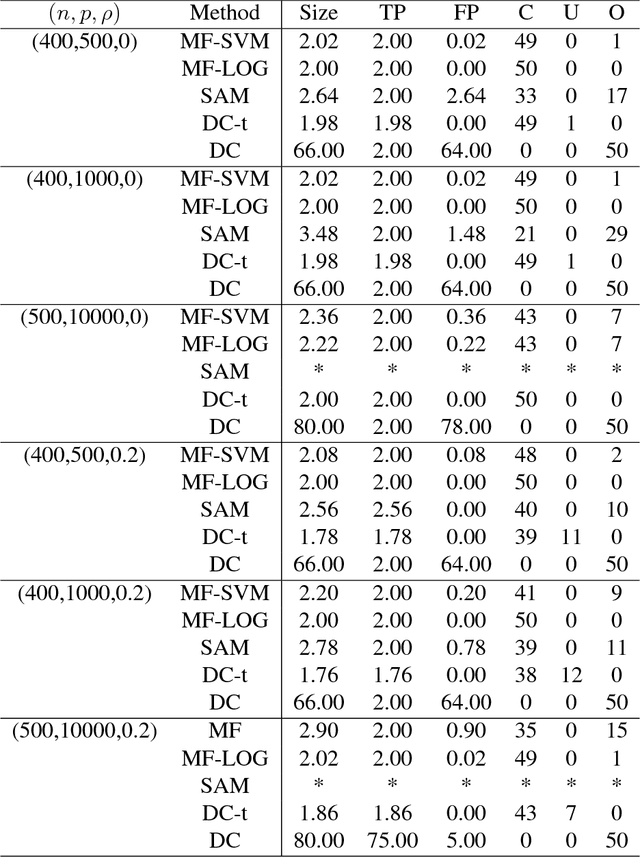

Sparse learning aims to learn the sparse structure of the true target function from the collected data, which plays a crucial role in high dimensional data analysis. This article proposes a unified and universal method for learning sparsity of M-estimators within a rich family of loss functions in a reproducing kernel Hilbert space (RKHS). The family of loss functions interested is very rich, including most commonly used ones in literature. More importantly, the proposed method is motivated by some nice properties in the induced RKHS, and is computationally efficient for large-scale data, and can be further improved through parallel computing. The asymptotic estimation and selection consistencies of the proposed method are established for a general loss function under mild conditions. It works for general loss function, admits general dependence structure, allows for efficient computation, and with theoretical guarantee. The superior performance of our proposed method is also supported by a variety of simulated examples and a real application in the human breast cancer study (GSE20194).