 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPGA-based Accelerators of Deep Learning Networks for Learning and Classification: A Review
Paper and Code
Jan 01, 2019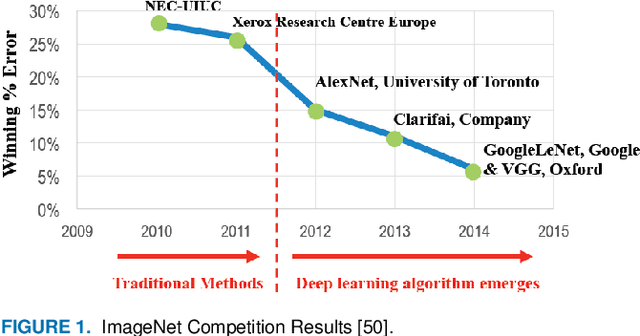
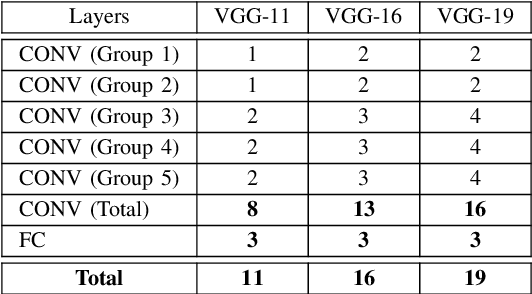
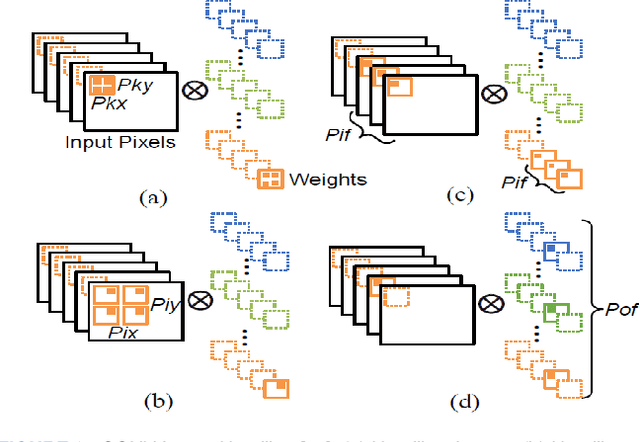
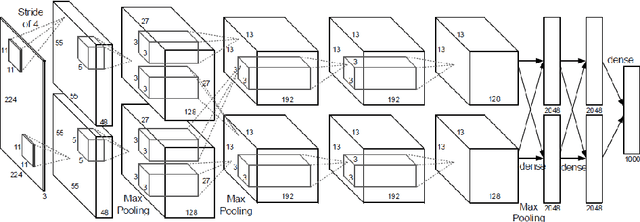
Due to recent advances in digital technologies, and availability of credible data, an area of artificial intelligence, deep learning, has emerged, and has demonstrated its ability and effectiveness in solving complex learning problems not possible before. In particular, convolution neural networks (CNNs) have demonstrated their effectiveness in image detection and recognition applications. However, they require intensive CPU operations and memory bandwidth that make general CPUs fail to achieve desired performance levels. Consequently, hardware accelerators that use application specific integrated circuits (ASICs), field programmable gate arrays (FPGAs), and graphic processing units (GPUs) have been employed to improve the throughput of CNNs. More precisely, FPGAs have been recently adopted for accelerating the implementation of deep learning networks due to their ability to maximize parallelism as well as due to their energy efficiency. In this paper, we review recent existing techniques for accelerating deep learning networks on FPGAs. We highlight the key features employed by the various techniques for improving the acceleration performance. In addition, we provide recommendations for enhancing the utilization of FPGAs for CNNs acceleration. The techniques investigated in this paper represent the recent trends in FPGA-based accelerators of deep learning networks. Thus, this review is expected to direct the future advances on efficient hardware accelerators and to be useful for deep learning researchers.