 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task learning to improve natural language understanding
Paper and Code
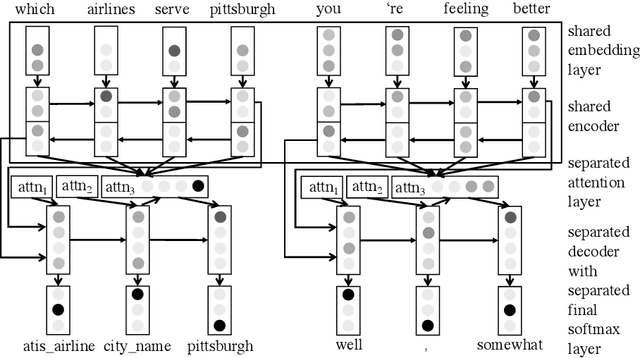
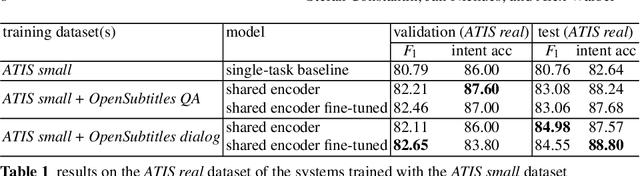

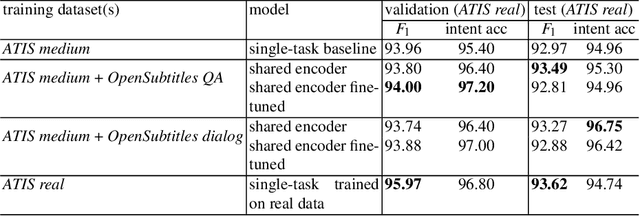
Recently advancements in sequence-to-sequence neural network architectures have led to an improved natural language understanding. When building a neural network-based Natural Language Understanding component, one main challenge is to collect enough training data. The generation of a synthetic dataset is an inexpensive and quick way to collect data. Since this data often has less variety than real natural language, neural networks often have problems to generalize to unseen utterances during testing. In this work, we address this challenge by using multi-task learning. We train out-of-domain real data alongside in-domain synthetic data to improve natural language understanding. We evaluate this approach in the domain of airline travel information with two synthetic datasets. As out-of-domain real data, we test two datasets based on the subtitles of movies and series. By using an attention-based encoder-decoder model, we were able to improve the F1-score over strong baselines from 80.76 % to 84.98 % in the smaller synthetic dataset.