 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Likelihood Implicit Quantile Network
Paper and Code
Jan 13, 2019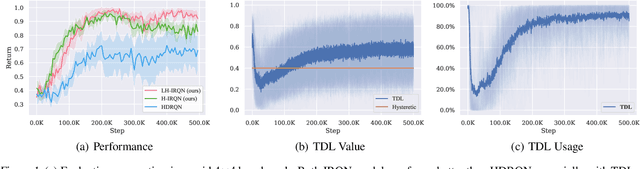
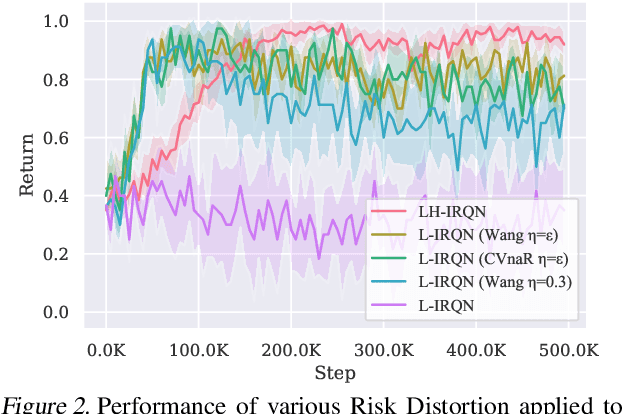
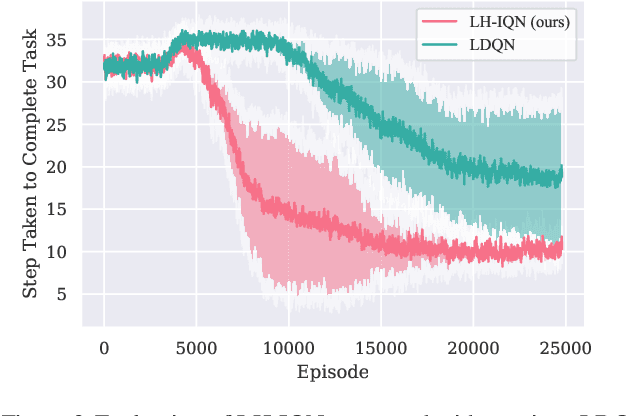
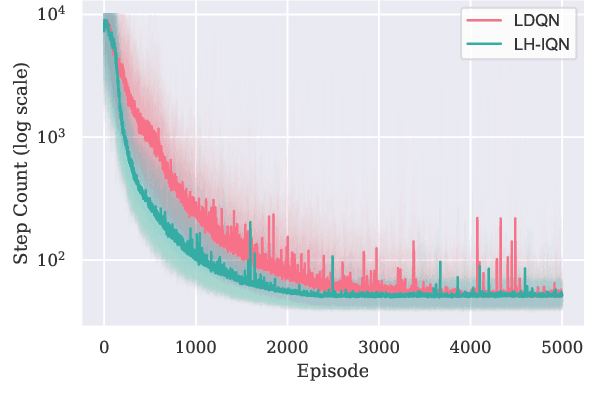
Recent successes of value-based multi-agent deep reinforcement learning employ optimism by limiting underestimation updates of value function estimator, through carefully controlled learning rate (Omidshafiei et al., 2017) or reduced update probability (Palmer et al., 2018). To achieve full cooperation when learning independently, an agent must estimate the state values contingent on having optimal teammates; therefore, value overestimation is frequency injected to counteract negative effects caused by unobservable teammate sub-optimal policies and explorations. Aiming to solve this issue through automatic scheduling, this paper introduces a decentralized quantile estimator, which we found empirically to be more stable, sample efficient and more likely to converge to the joint optimal policy.