 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Transfer Learning for Named Entity Recognition
Paper and Code
Jan 18, 2019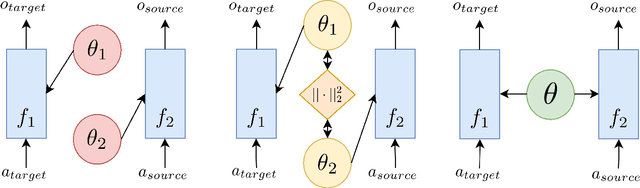
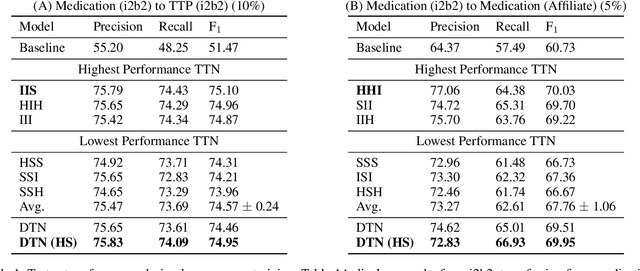
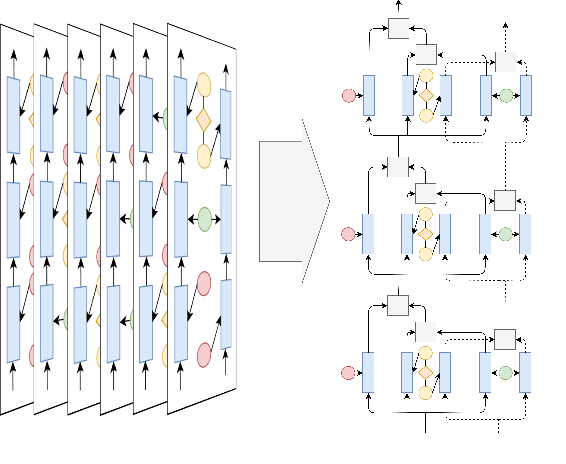
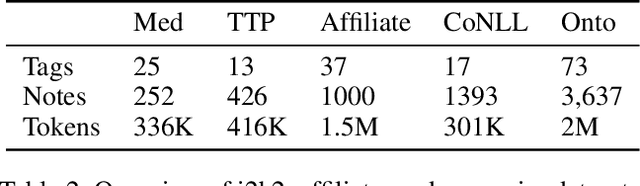
State-of-the-art named entity recognition (NER) systems have been improving continuously using neural architectures over the past several years. However, many tasks including NER require large sets of annotated data to achieve such performance. In particular, we focus on NER from clinical notes, which is one of the most fundamental and critical problems for medical text analysis. Our work centers on effectively adapting these neural architectures towards low-resource settings using parameter transfer methods. We complement a standard hierarchical NER model with a general transfer learning framework consisting of parameter sharing between the source and target tasks, and showcase scores significantly above the baseline architecture. These sharing schemes require an exponential search over tied parameter sets to generate an optimal configuration. To mitigate the problem of exhaustively searching for model optimization, we propose the Dynamic Transfer Networks (DTN), a gated architecture which learns the appropriate parameter sharing scheme between source and target datasets. DTN achieves the improvements of the optimized transfer learning framework with just a single training setting, effectively removing the need for exponential search.