 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-based Navigation with Language-based Assistance via Imitation Learning with Indirect Intervention
Paper and Code

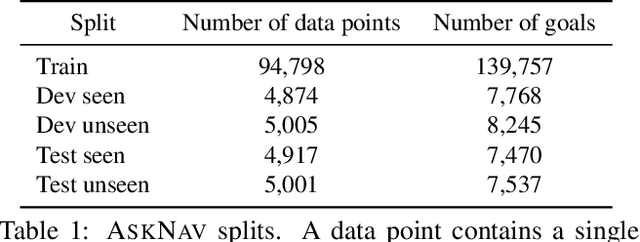
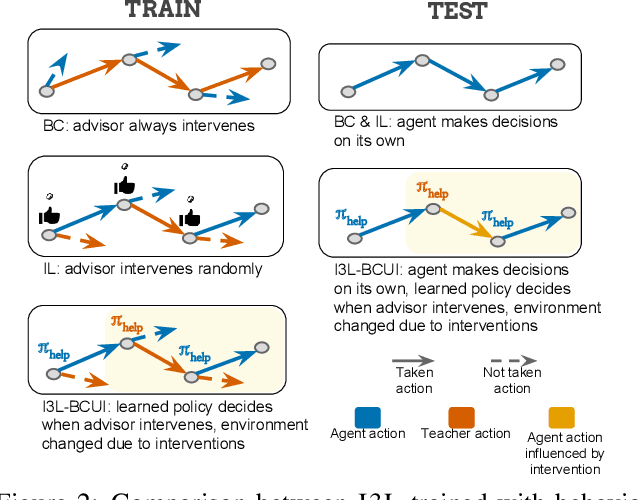
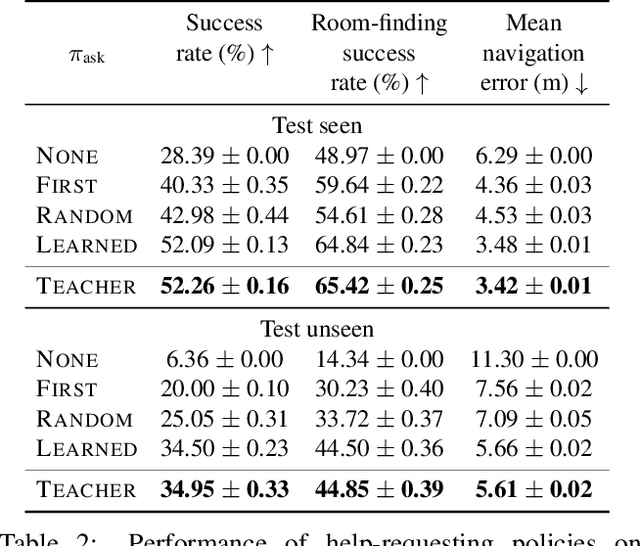
We present Vision-based Navigation with Language-based Assistance (VNLA), a grounded vision-language task where an agent with visual perception is guided via language to find objects in photorealistic indoor environments. The task emulates a real-world scenario in that (a) the requester may not know how to navigate to the target objects and thus makes requests by only specifying high-level end-goals, and (b) the agent is capable of sensing when it is lost and querying an advisor, who is more qualified at the task, to obtain language subgoals to make progress. To model language-based assistance, we develop a general framework termed Imitation Learning with Indirect Intervention (I3L), and propose a solution that is effective on the VNLA task. Empirical results show that this approach significantly improves the success rate of the learning agent over other baselines in both seen and unseen environments. Our code and data are publicly available at https://github.com/debadeepta/vnla .