 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDF: Ensemble, Distill, and Fuse for Easy Video Labeling
Paper and Code
Dec 10, 2018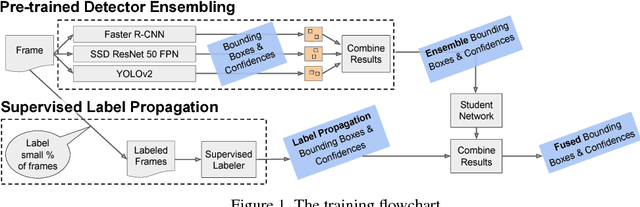
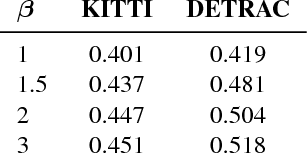
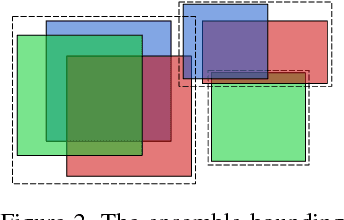

We present a way to rapidly bootstrap object detection on unseen videos using minimal human annotations. We accomplish this by combining two complementary sources of knowledge (one generic and the other specific) using bounding box merging and model distillation. The first (generic) knowledge source is obtained from ensembling pre-trained object detectors using a novel bounding box merging and confidence reweighting scheme. We make the observation that model distillation with data augmentation can train a specialized detector that outperforms the noisy labels it was trained on, and train a Student Network on the ensemble detections that obtains higher mAP than the ensemble itself. The second (specialized) knowledge source comes from training a detector (which we call the Supervised Labeler) on a labeled subset of the video to generate detections on the unlabeled portion. We demonstrate on two popular vehicular datasets that these techniques work to emit bounding boxes for all vehicles in the frame with higher mean average precision (mAP) than any of the reference networks used, and that the combination of ensembled and human-labeled data produces object detections that outperform either alone.