 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Model Distillation for Efficient Video Inference
Paper and Code
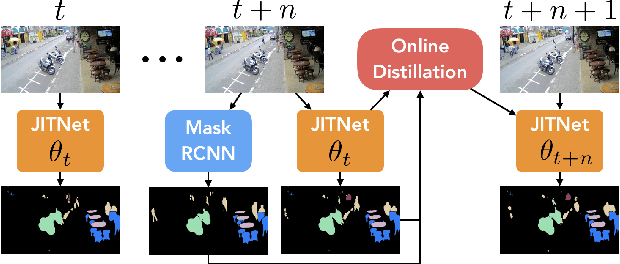
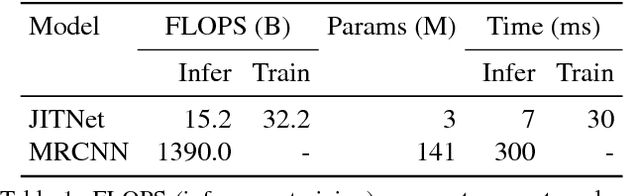
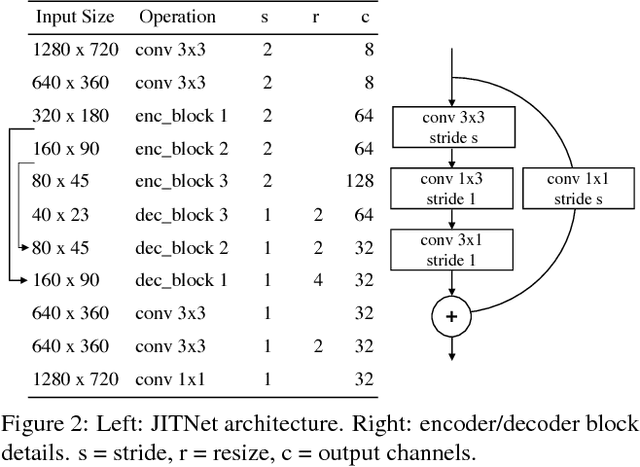
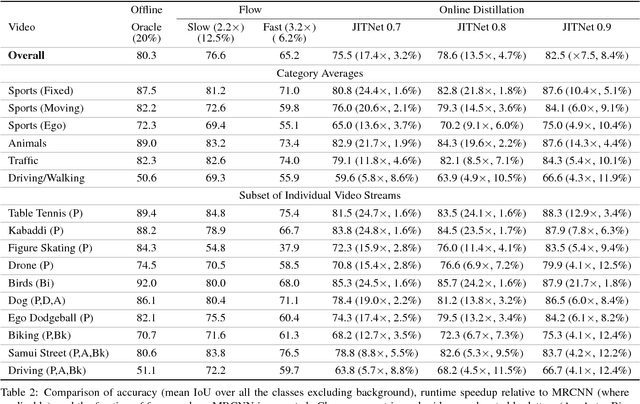
High-quality computer vision models typically address the problem of understanding the general distribution of real-world images. However, most cameras observe only a very small fraction of this distribution. This offers the possibility of achieving more efficient inference by specializing compact, low-cost models to the specific distribution of frames observed by a single camera. In this paper, we employ the technique of model distillation (supervising a low-cost student model using the output of a high-cost teacher) to specialize accurate, low-cost semantic segmentation models to a target video stream. Rather than learn a specialized student model on offline data from the video stream, we train the student in an online fashion on the live video, intermittently running the teacher to provide a target for learning. Online model distillation yields semantic segmentation models that closely approximate their Mask R-CNN teacher with 7 to 17x lower inference runtime cost (11 to 26x in FLOPs), even when the target video's distribution is non-stationary. Our method requires no offline pretraining on the target video stream, and achieves higher accuracy and lower cost than solutions based on flow or video object segmentation. We also provide a new video dataset for evaluating the efficiency of inference over long running video streams.