 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetect-to-Retrieve: Efficient Regional Aggregation for Image Search
Paper and Code
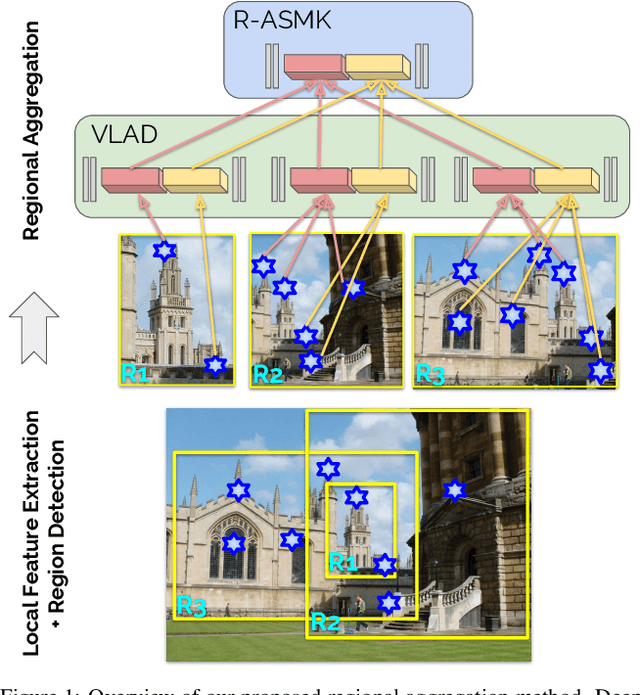
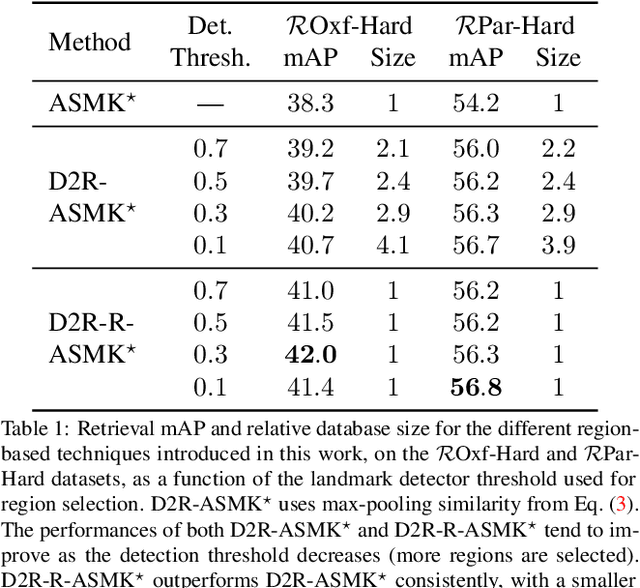

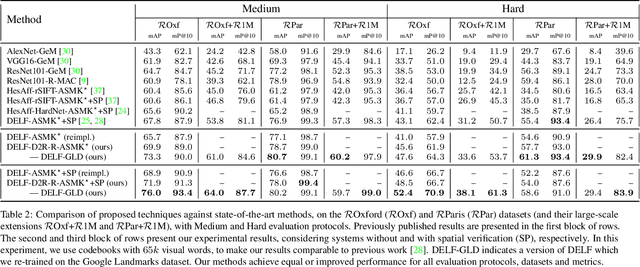
Retrieving object instances among cluttered scenes efficiently requires compact yet comprehensive regional image representations. Intuitively, object semantics can help build the index that focuses on the most relevant regions. However, due to the lack of bounding-box datasets for objects of interest among retrieval benchmarks, most recent work on regional representations has focused on either uniform or class-agnostic region selection. In this paper, we first fill the void by providing a new dataset of landmark bounding boxes, based on the Google Landmarks dataset, that includes $94k$ images with manually curated boxes from $15k$ unique landmarks. Then, we demonstrate how a trained landmark detector, using our new dataset, can be leveraged to index image regions and improve retrieval accuracy while being much more efficient than existing regional methods. In addition, we further introduce a novel regional aggregated selective match kernel (R-ASMK) to effectively combine information from detected regions into an improved holistic image representation. R-ASMK boosts image retrieval accuracy substantially at no additional memory cost, while even outperforming systems that index image regions independently. Our complete image retrieval system improves upon the previous state-of-the-art by significant margins on the Revisited Oxford and Paris datasets. Code and data will be released.