 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Visual Centrifuge: Model-Free Layered Video Representations
Paper and Code
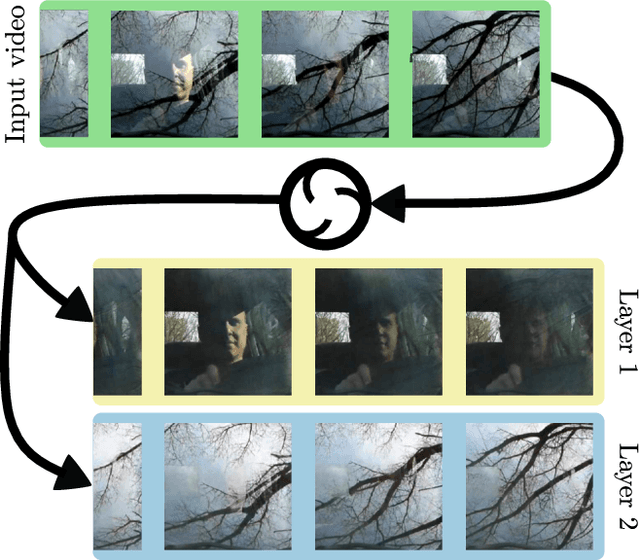

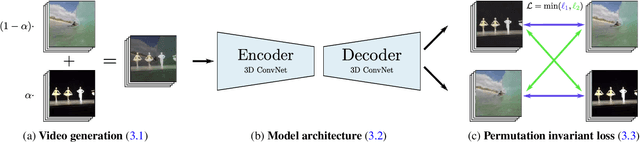
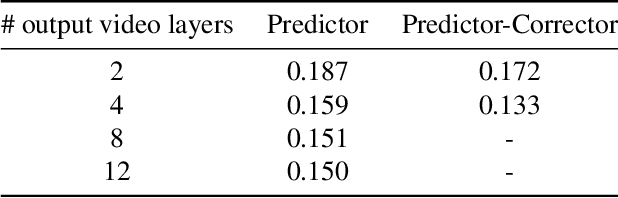
True video understanding requires making sense of non-lambertian scenes where the color of light arriving at the camera sensor encodes information about not just the last object it collided with, but about multiple mediums -- colored windows, dirty mirrors, smoke or rain. Layered video representations have the potential of accurately modelling realistic scenes but have so far required stringent assumptions on motion, lighting and shape. Here we propose a learning-based approach for multi-layered video representation: we introduce novel uncertainty-capturing 3D convolutional architectures and train them to separate blended videos. We show that these models then generalize to single videos, where they exhibit interesting abilities: color constancy, factoring out shadows and separating reflections. We present quantitative and qualitative results on real world videos.