 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Capsule Routing for Actor and Action Video Segmentation Conditioned on Natural Language Queries
Paper and Code
Dec 02, 2018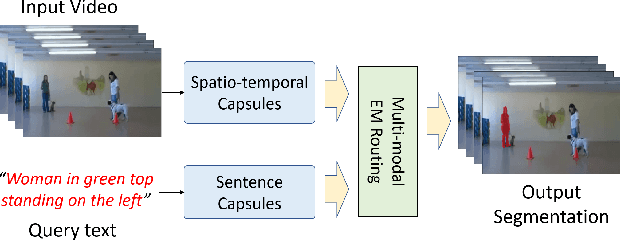
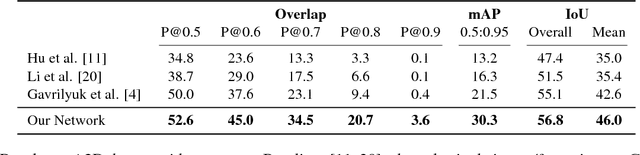
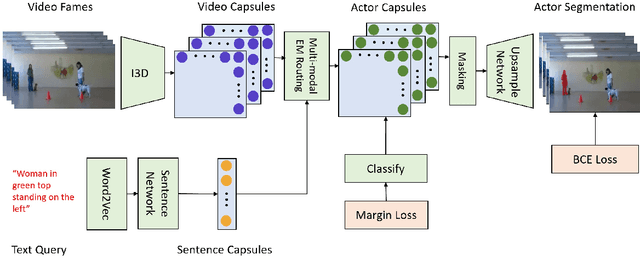
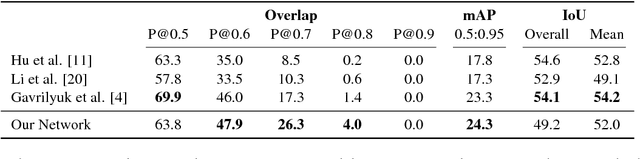
In this paper, we propose an end-to-end capsule network for pixel level localization of actors and actions present in a video. The localization is performed based on a natural language query through which an actor and action are specified. We propose to encode both the video as well as textual input in the form of capsules, which provide more effective representation in comparison with standard convolution based features. We introduce a novel capsule based attention mechanism for fusion of video and text capsules for text selected video segmentation. The attention mechanism is performed via joint EM routing over video and text capsules for text selected actor and action localization. The existing works on actor-action localization are mainly focused on localization in a single frame instead of the full video. Different from existing works, we propose to perform the localization on all frames of the video. To validate the potential of the proposed network for actor and action localization on all the frames of a video, we extend an existing actor-action dataset (A2D) with annotations for all the frames. The experimental evaluation demonstrates the effectiveness of the proposed capsule network for text selective actor and action localization in videos, and it also improves upon the performance of the existing state-of-the art works on single frame-based localization.