 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Organize your Deep Reinforcement Learning Agents: The Importance of Communication Topology
Paper and Code
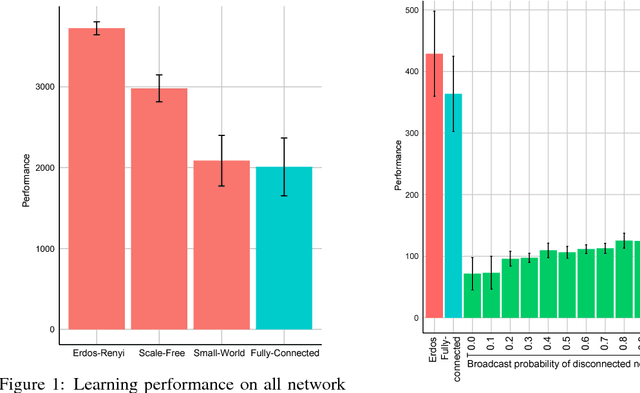

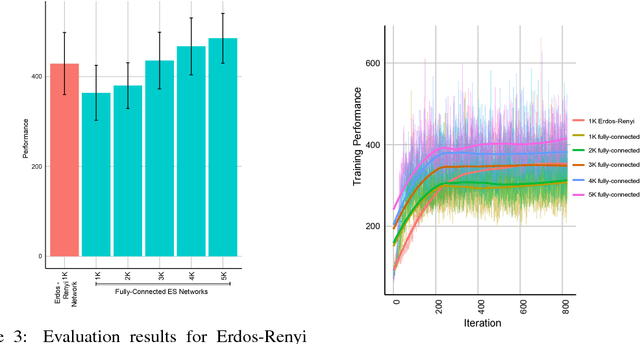
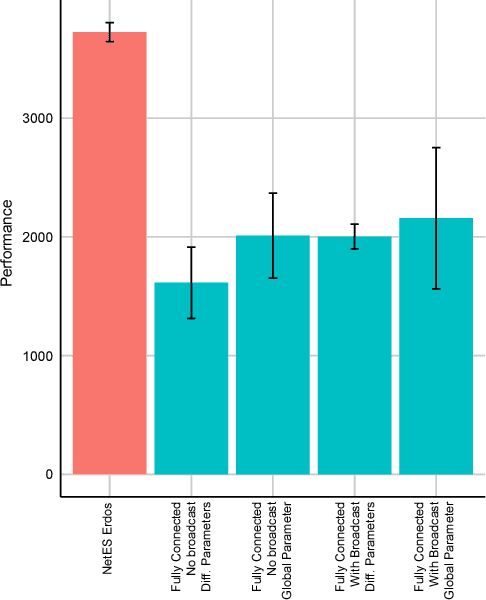
In this empirical paper, we investigate how learning agents can be arranged in more efficient communication topologies for improved learning. This is an important problem because a common technique to improve speed and robustness of learning in deep reinforcement learning and many other machine learning algorithms is to run multiple learning agents in parallel. The standard communication architecture typically involves all agents intermittently communicating with each other (fully connected topology) or with a centralized server (star topology). Unfortunately, optimizing the topology of communication over the space of all possible graphs is a hard problem, so we borrow results from the networked optimization and collective intelligence literatures which suggest that certain families of network topologies can lead to strong improvements over fully-connected networks. We start by introducing alternative network topologies to DRL benchmark tasks under the Evolution Strategies paradigm which we call Network Evolution Strategies. We explore the relative performance of the four main graph families and observe that one such family (Erdos-Renyi random graphs) empirically outperforms all other families, including the de facto fully-connected communication topologies. Additionally, the use of alternative network topologies has a multiplicative performance effect: we observe that when 1000 learning agents are arranged in a carefully designed communication topology, they can compete with 3000 agents arranged in the de facto fully-connected topology. Overall, our work suggests that distributed machine learning algorithms would learn more efficiently if the communication topology between learning agents was optimized.