 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Embedding Induced Text Clustering, a Non-parametric Bayesian Approach
Paper and Code
Nov 29, 2018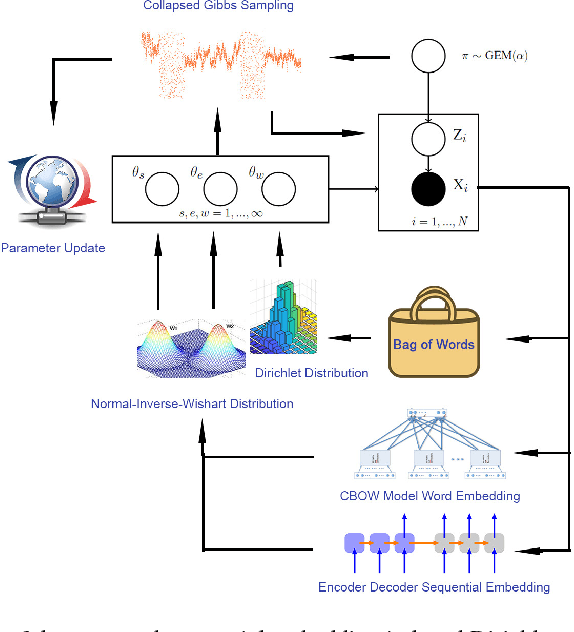

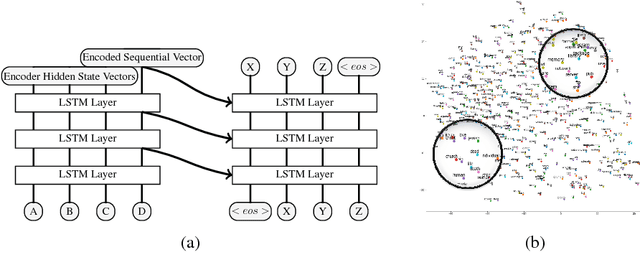
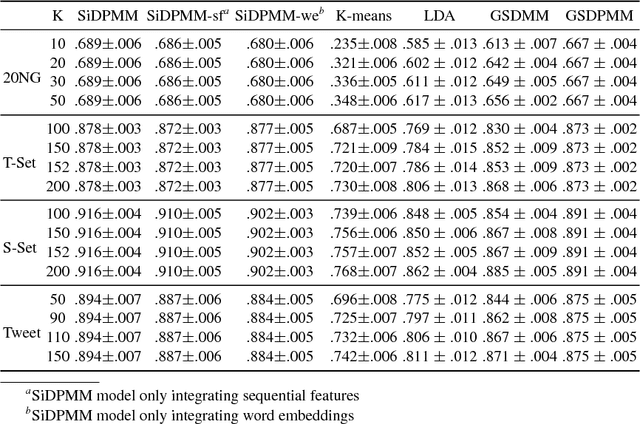
Current state-of-the-art nonparametric Bayesian text clustering methods model documents through multinomial distribution on bags of words. Although these methods can effectively utilize the word burstiness representation of documents and achieve decent performance, they do not explore the sequential information of text and relationships among synonyms. In this paper, the documents are modeled as the joint of bags of words, sequential features and word embeddings. We proposed Sequential Embedding induced Dirichlet Process Mixture Model (SiDPMM) to effectively exploit this joint document representation in text clustering. The sequential features are extracted by the encoder-decoder component. Word embeddings produced by the continuous-bag-of-words (CBOW) model are introduced to handle synonyms. Experimental results demonstrate the benefits of our model in two major aspects: 1) improved performance across multiple diverse text datasets in terms of the normalized mutual information (NMI); 2) more accurate inference of ground truth cluster numbers with regularization effect on tiny outlier clusters.