 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-parallel distributed training of very large models beyond GPU capacity
Paper and Code
Nov 29, 2018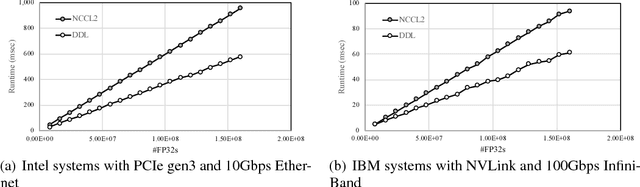

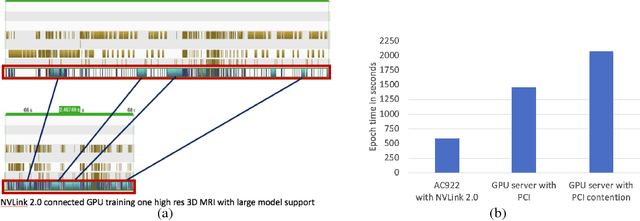

GPUs have limited memory and it is difficult to train wide and/or deep models that cause the training process to go out of memory. It is shown in this paper how an open source tool called Large Model Support (LMS) can utilize a high bandwidth NVLink connection between CPUs and GPUs to accomplish training of deep convolutional networks. LMS performs tensor swapping between CPU memory and GPU memory such that only a minimal number of tensors required in a training step are kept in the GPU memory. It is also shown how LMS can be combined with an MPI based distributed deep learning module to train models in a data-parallel fashion across multiple GPUs, such that each GPU is utilizing the CPU memory for tensor swapping. The hardware architecture that enables the high bandwidth GPU link with the CPU is discussed as well as the associated set of software tools that are available as the PowerAI package.