 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning of Pedestrian Trajectories Using Actor-Critic Sequence-to-Sequence Autoencoder
Paper and Code
Nov 20, 2018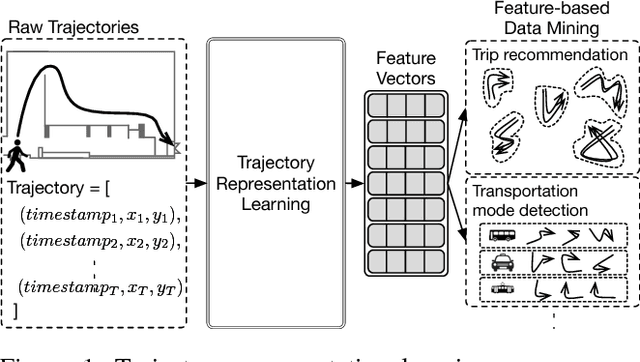
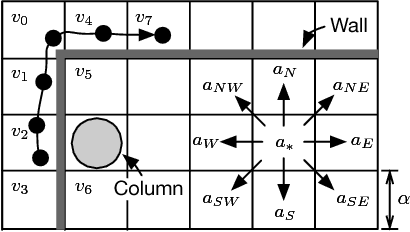
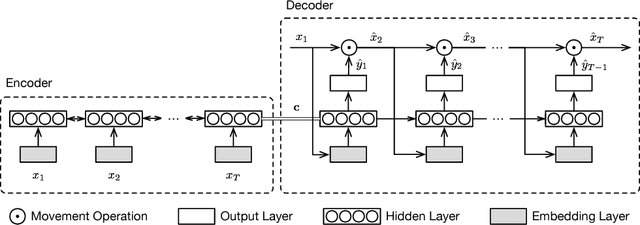
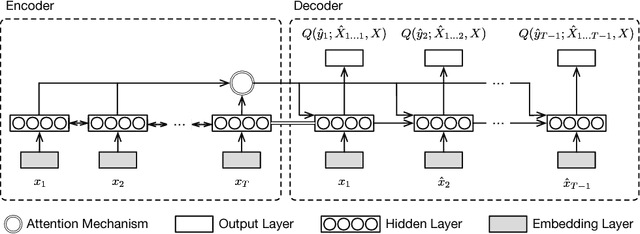
Representation learning of pedestrian trajectories transforms variable-length timestamp-coordinate tuples of a trajectory into a fixed-length vector representation that summarizes spatiotemporal characteristics. It is a crucial technique to connect feature-based data mining with trajectory data. Trajectory representation is a challenging problem, because both environmental constraints (e.g., wall partitions) and temporal user dynamics should be meticulously considered and accounted for. Furthermore, traditional sequence-to-sequence autoencoders using maximum log-likelihood often require dataset covering all the possible spatiotemporal characteristics to perform well. This is infeasible or impractical in reality. We propose TREP, a practical pedestrian trajectory representation learning algorithm which captures the environmental constraints and the pedestrian dynamics without the need of any training dataset. By formulating a sequence-to-sequence autoencoder with a spatial-aware objective function under the paradigm of actor-critic reinforcement learning, TREP intelligently encodes spatiotemporal characteristics of trajectories with the capability of handling diverse trajectory patterns. Extensive experiments on both synthetic and real datasets validate the high fidelity of TREP to represent trajectories.