 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Geometric Perspective on the Transferability of Adversarial Directions
Paper and Code
Nov 08, 2018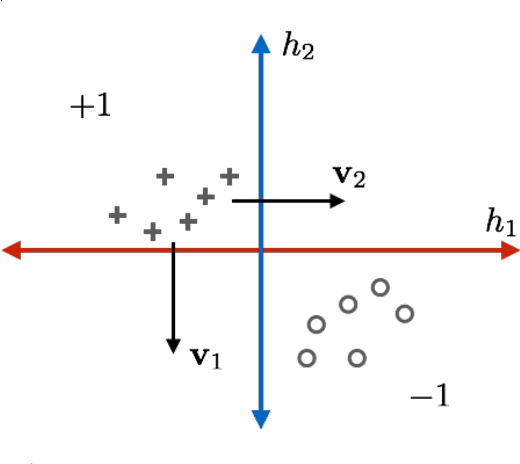
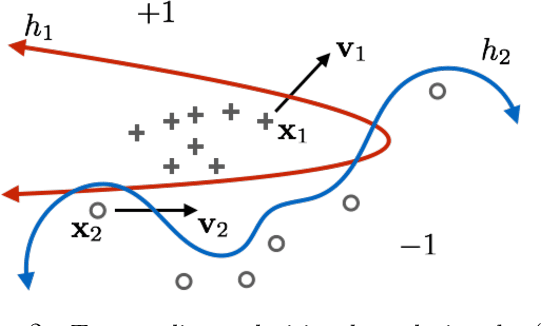
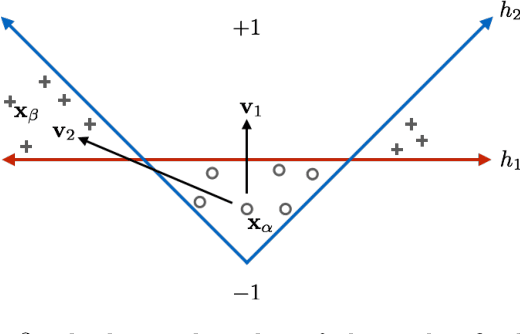
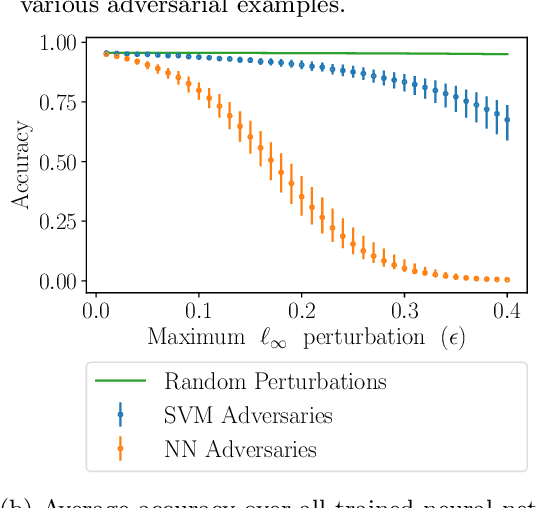
State-of-the-art machine learning models frequently misclassify inputs that have been perturbed in an adversarial manner. Adversarial perturbations generated for a given input and a specific classifier often seem to be effective on other inputs and even different classifiers. In other words, adversarial perturbations seem to transfer between different inputs, models, and even different neural network architectures. In this work, we show that in the context of linear classifiers and two-layer ReLU networks, there provably exist directions that give rise to adversarial perturbations for many classifiers and data points simultaneously. We show that these "transferable adversarial directions" are guaranteed to exist for linear separators of a given set, and will exist with high probability for linear classifiers trained on independent sets drawn from the same distribution. We extend our results to large classes of two-layer ReLU networks. We further show that adversarial directions for ReLU networks transfer to linear classifiers while the reverse need not hold, suggesting that adversarial perturbations for more complex models are more likely to transfer to other classifiers. We validate our findings empirically, even for deeper ReLU networks.