 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfusion2Vec: Towards Enriching Vector Space Word Representations with Representational Ambiguities
Paper and Code
Nov 08, 2018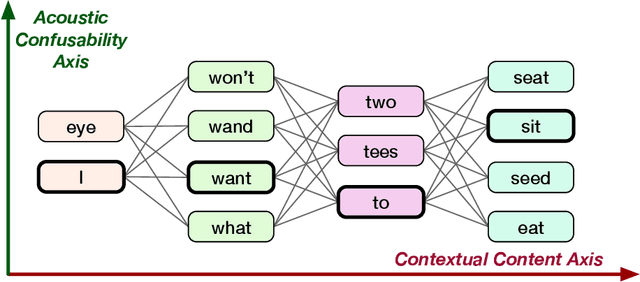
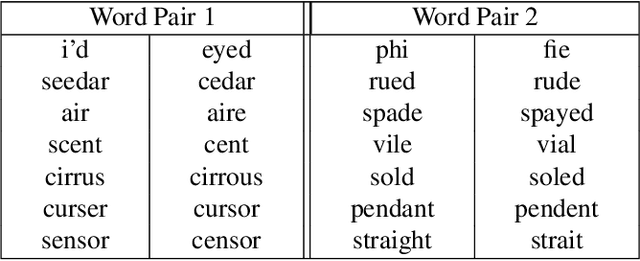
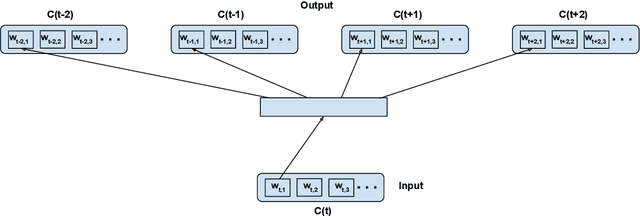
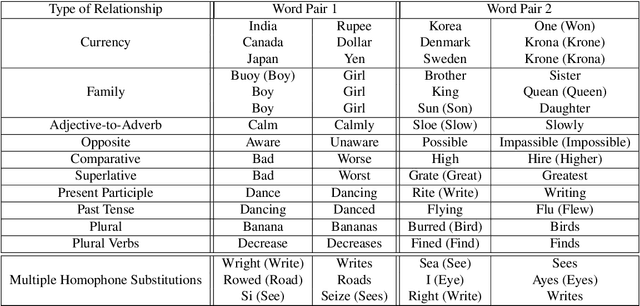
Word vector representations are a crucial part of Natural Language Processing (NLP) and Human Computer Interaction. In this paper, we propose a novel word vector representation, Confusion2Vec, motivated from the human speech production and perception that encodes representational ambiguity. Humans employ both acoustic similarity cues and contextual cues to decode information and we focus on a model that incorporates both sources of information. The representational ambiguity of acoustics, which manifests itself in word confusions, is often resolved by both humans and machines through contextual cues. A range of representational ambiguities can emerge in various domains further to acoustic perception, such as morphological transformations, paraphrasing for NLP tasks like machine translation etc. In this work, we present a case study in application to Automatic Speech Recognition (ASR), where the word confusions are related to acoustic similarity. We present several techniques to train an acoustic perceptual similarity representation ambiguity. We term this Confusion2Vec and learn on unsupervised-generated data from ASR confusion networks or lattice-like structures. Appropriate evaluations for the Confusion2Vec are formulated for gauging acoustic similarity in addition to semantic-syntactic and word similarity evaluations. The Confusion2Vec is able to model word confusions efficiently, without compromising on the semantic-syntactic word relations, thus effectively enriching the word vector space with extra task relevant ambiguity information. We provide an intuitive exploration of the 2-dimensional Confusion2Vec space using Principal Component Analysis of the embedding and relate to semantic, syntactic and acoustic relationships. The potential of Confusion2Vec in the utilization of uncertainty present in lattices is demonstrated through small examples relating to ASR error correction.