 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-armed Bandits with Compensation
Paper and Code
Nov 05, 2018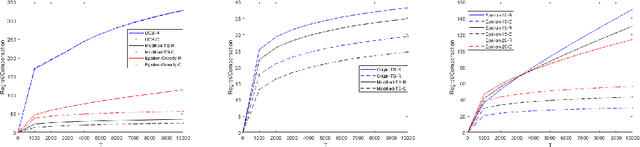
We propose and study the known-compensation multi-arm bandit (KCMAB) problem, where a system controller offers a set of arms to many short-term players for $T$ steps. In each step, one short-term player arrives to the system. Upon arrival, the player aims to select an arm with the current best average reward and receives a stochastic reward associated with the arm. In order to incentivize players to explore other arms, the controller provides a proper payment compensation to players. The objective of the controller is to maximize the total reward collected by players while minimizing the compensation. We first provide a compensation lower bound $\Theta(\sum_i {\Delta_i\log T\over KL_i})$, where $\Delta_i$ and $KL_i$ are the expected reward gap and Kullback-Leibler (KL) divergence between distributions of arm $i$ and the best arm, respectively. We then analyze three algorithms to solve the KCMAB problem, and obtain their regrets and compensations. We show that the algorithms all achieve $O(\log T)$ regret and $O(\log T)$ compensation that match the theoretical lower bound. Finally, we present experimental results to demonstrate the performance of the algorithms.