 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering and Learning from Imbalanced Data
Paper and Code
Nov 02, 2018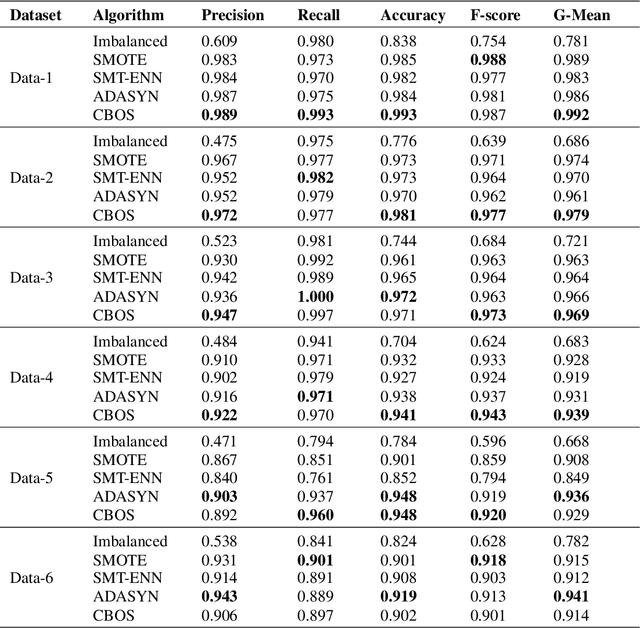
A learning classifier must outperform a trivial solution, in case of imbalanced data, this condition usually does not hold true. To overcome this problem, we propose a novel data level resampling method - Clustering Based Oversampling for improved learning from class imbalanced datasets. The essential idea behind the proposed method is to use the distance between a minority class sample and its respective cluster centroid to infer the number of new sample points to be generated for that minority class sample. The proposed algorithm has very less dependence on the technique used for finding cluster centroids and does not effect the majority class learning in any way. It also improves learning from imbalanced data by incorporating the distribution structure of minority class samples in generation of new data samples. The newly generated minority class data is handled in a way as to prevent outlier production and overfitting. Implementation analysis on different datasets using deep neural networks as the learning classifier shows the effectiveness of this method as compared to other synthetic data resampling techniques across several evaluation metrics.