 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaking style adaptation in Text-To-Speech synthesis using Sequence-to-sequence models with attention
Paper and Code
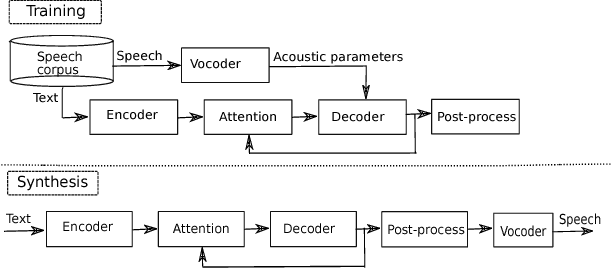
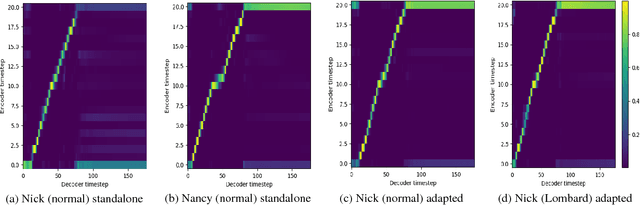

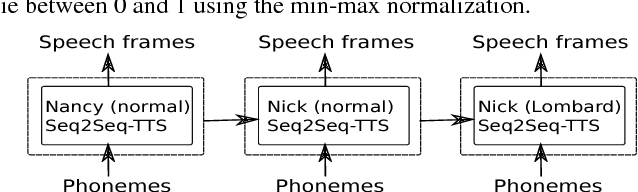
Currently, there are increasing interests in text-to-speech (TTS) synthesis to use sequence-to-sequence models with attention. These models are end-to-end meaning that they learn both co-articulation and duration properties directly from text and speech. Since these models are entirely data-driven, they need large amounts of data to generate synthetic speech with good quality. However, in challenging speaking styles, such as Lombard speech, it is difficult to record sufficiently large speech corpora. Therefore, in this study we propose a transfer learning method to adapt a sequence-to-sequence based TTS system of normal speaking style to Lombard style. Moreover, we experiment with a WaveNet vocoder in synthesis of Lombard speech. We conducted subjective evaluations to assess the performance of the adapted TTS systems. The subjective evaluation results indicated that an adaptation system with the WaveNet vocoder clearly outperformed the conventional deep neural network based TTS system in synthesis of Lombard speech.