 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgeSpeechNets: Highly Efficient Deep Neural Networks for Speech Recognition on the Edge
Paper and Code
Oct 18, 2018
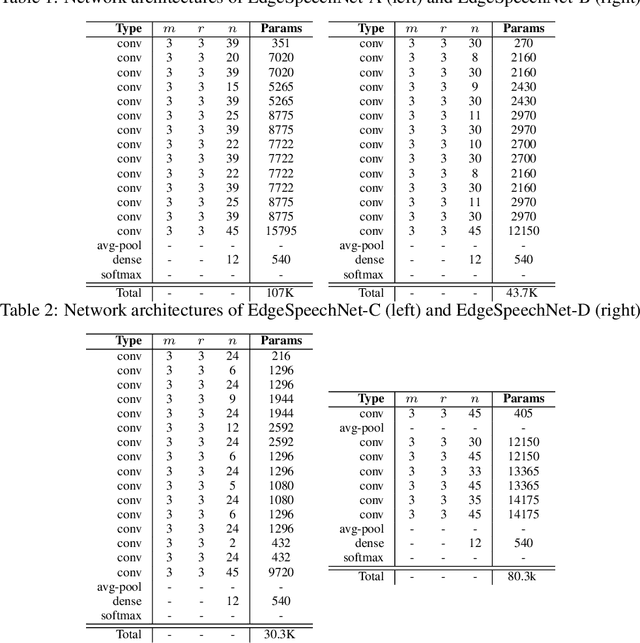
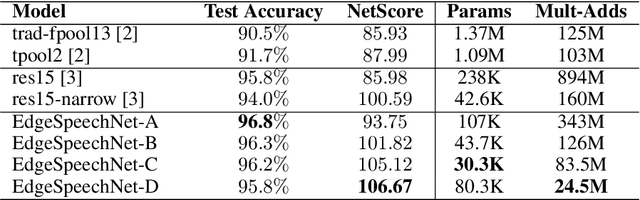
Despite showing state-of-the-art performance, deep learning for speech recognition remains challenging to deploy in on-device edge scenarios such as mobile and other consumer devices. Recently, there have been greater efforts in the design of small, low-footprint deep neural networks (DNNs) that are more appropriate for edge devices, with much of the focus on design principles for hand-crafting efficient network architectures. In this study, we explore a human-machine collaborative design strategy for building low-footprint DNN architectures for speech recognition through a marriage of human-driven principled network design prototyping and machine-driven design exploration. The efficacy of this design strategy is demonstrated through the design of a family of highly-efficient DNNs (nicknamed EdgeSpeechNets) for limited-vocabulary speech recognition. Experimental results using the Google Speech Commands dataset for limited-vocabulary speech recognition showed that EdgeSpeechNets have higher accuracies than state-of-the-art DNNs (with the best EdgeSpeechNet achieving ~97% accuracy), while achieving significantly smaller network sizes (as much as 7.8x smaller) and lower computational cost (as much as 36x fewer multiply-add operations, 10x lower prediction latency, and 16x smaller memory footprint on a Motorola Moto E phone), making them very well-suited for on-device edge voice interface applications.