 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust Region Policy Optimization of POMDPs
Paper and Code
Oct 18, 2018
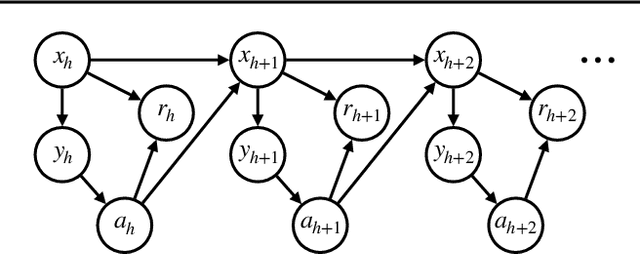
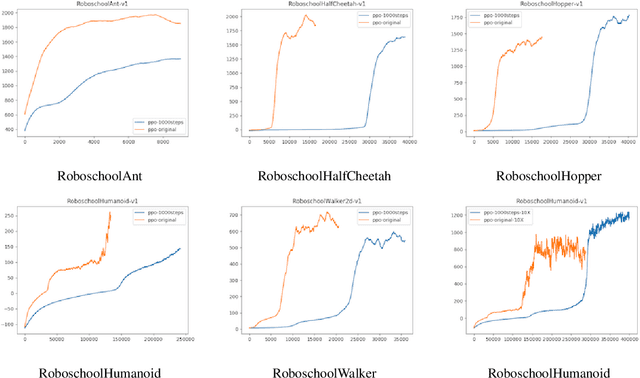
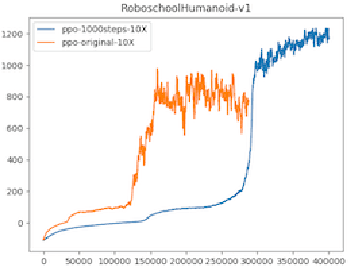
We propose Generalized Trust Region Policy Optimization (GTRPO), a Reinforcement Learning algorithm for TRPO of Partially Observable Markov Decision Processes (POMDP). While the principle of policy gradient methods does not require any model assumption, previous studies of more sophisticated policy gradient methods are mainly limited to MDPs. Many real-world decision-making tasks, however, are inherently non-Markovian, i.e., only an incomplete representation of the environment is observable. Moreover, most of the advanced policy gradient methods are designed for infinite horizon MDPs. Our proposed algorithm, GTRPO, is a policy gradient method for continuous episodic POMDPs. We prove that its policy updates monotonically improve the expected cumulative return. We empirically study GTRPO on many RoboSchool environments, an extension to the MuJoCo environments, and provide insights into its empirical behavior.