 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite sample expressive power of small-width ReLU networks
Paper and Code
Oct 17, 2018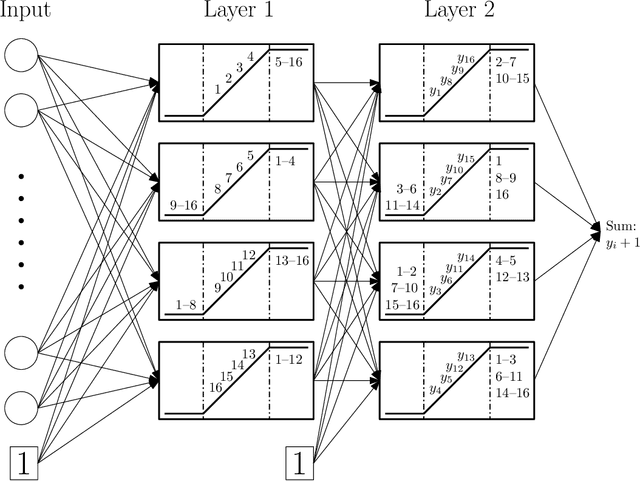
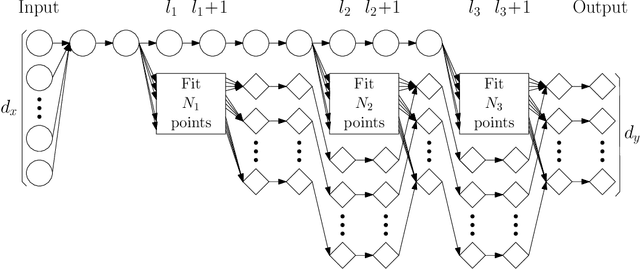
We study universal finite sample expressivity of neural networks, defined as the capability to perfectly memorize arbitrary datasets. For scalar outputs, existing results require a hidden layer as wide as $N$ to memorize $N$ data points. In contrast, we prove that a 3-layer (2-hidden-layer) ReLU network with $4 \sqrt {N}$ hidden nodes can perfectly fit any arbitrary dataset. For $K$-class classification, we prove that a 4-layer ReLU network with $4 \sqrt{N} + 4K$ hidden neurons can memorize arbitrary datasets. For example, a 4-layer ReLU network with only 8,000 hidden nodes can memorize datasets with $N$ = 1M and $K$ = 1k (e.g., ImageNet). Our results show that even small networks already have tremendous overfitting capability, admitting zero empirical risk for any dataset. We also extend our results to deeper and narrower networks, and prove converse results showing necessity of $\Omega(N)$ parameters for shallow networks.