 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting computational reproducibility of data analysis pipelines in large population studies using collaborative filtering
Paper and Code
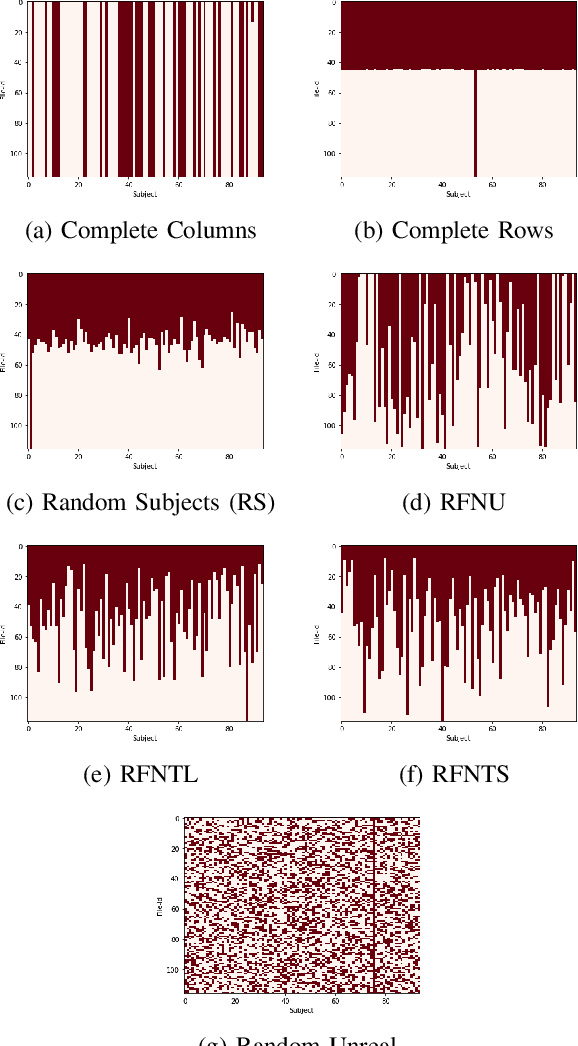
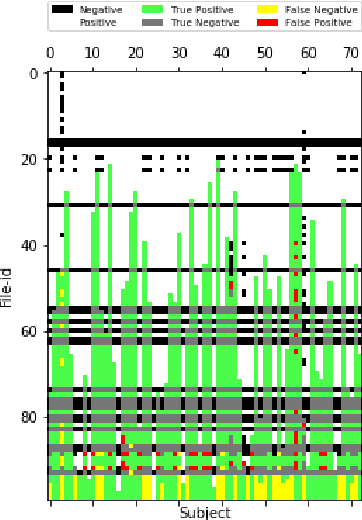
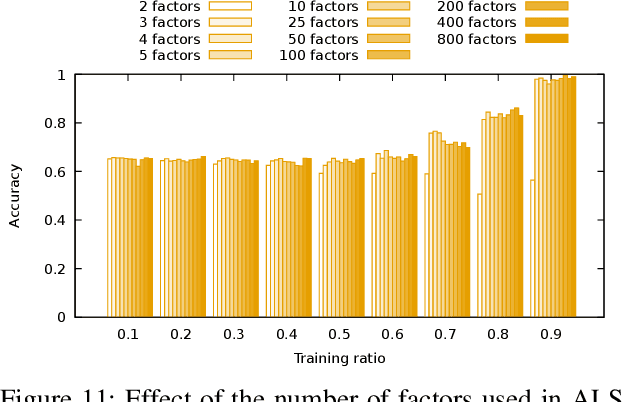
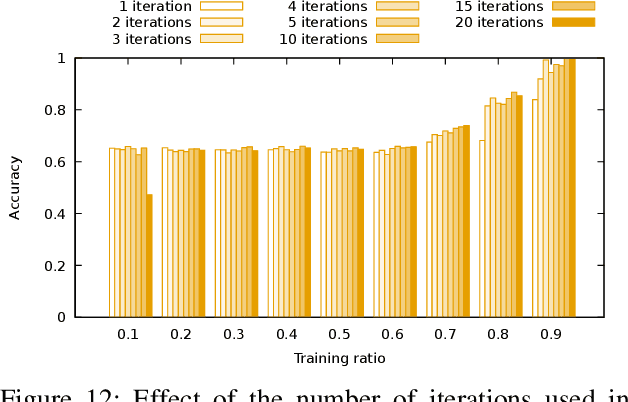
Evaluating the computational reproducibility of data analysis pipelines has become a critical issue. It is, however, a cumbersome process for analyses that involve data from large populations of subjects, due to their computational and storage requirements. We present a method to predict the computational reproducibility of data analysis pipelines in large population studies. We formulate the problem as a collaborative filtering process, with constraints on the construction of the training set. We propose 6 different strategies to build the training set, which we evaluate on 2 datasets, a synthetic one modeling a population with a growing number of subject types, and a real one obtained with neuroinformatics pipelines. Results show that one sampling method, "Random File Numbers (Uniform)" is able to predict computational reproducibility with a good accuracy. We also analyze the relevance of including file and subject biases in the collaborative filtering model. We conclude that the proposed method is able to speedup reproducibility evaluations substantially, with a reduced accuracy loss.