 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Safe than Sorry: Evidence Accumulation Allows for Safe Reinforcement Learning
Paper and Code
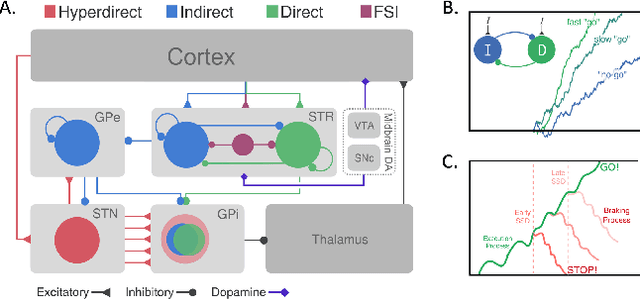
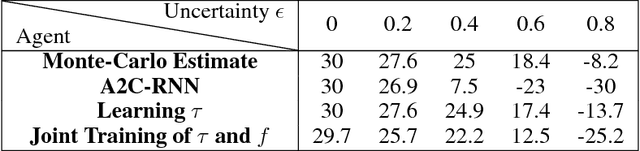
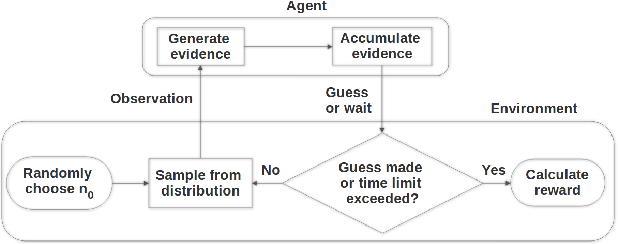
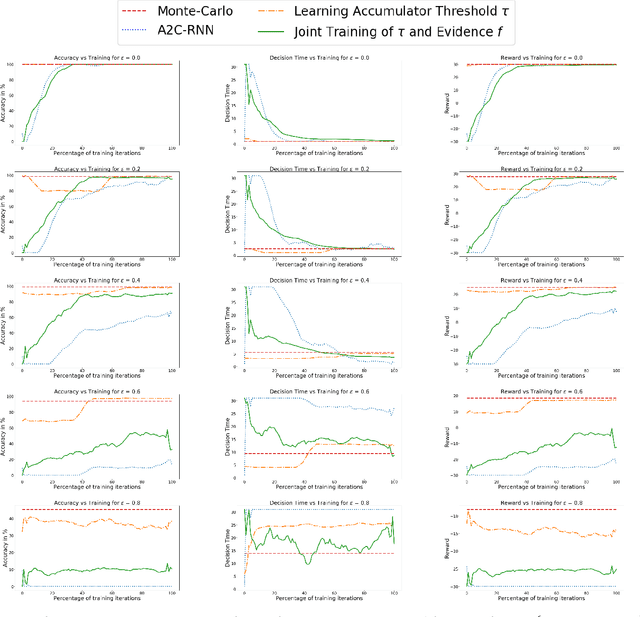
In the real world, agents often have to operate in situations with incomplete information, limited sensing capabilities, and inherently stochastic environments, making individual observations incomplete and unreliable. Moreover, in many situations it is preferable to delay a decision rather than run the risk of making a bad decision. In such situations it is necessary to aggregate information before taking an action; however, most state of the art reinforcement learning (RL) algorithms are biased towards taking actions \textit{at every time step}, even if the agent is not particularly confident in its chosen action. This lack of caution can lead the agent to make critical mistakes, regardless of prior experience and acclimation to the environment. Motivated by theories of dynamic resolution of uncertainty during decision making in biological brains, we propose a simple accumulator module which accumulates evidence in favor of each possible decision, encodes uncertainty as a dynamic competition between actions, and acts on the environment only when it is sufficiently confident in the chosen action. The agent makes no decision by default, and the burden of proof to make a decision falls on the policy to accrue evidence strongly in favor of a single decision. Our results show that this accumulator module achieves near-optimal performance on a simple guessing game, far outperforming deep recurrent networks using traditional, forced action selection policies.