Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExponential Convergence Time of Gradient Descent for One-Dimensional Deep Linear Neural Networks
Paper and Code
Sep 27, 2018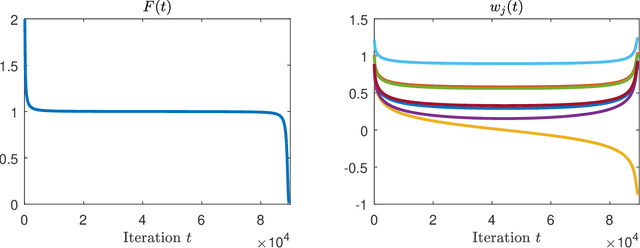
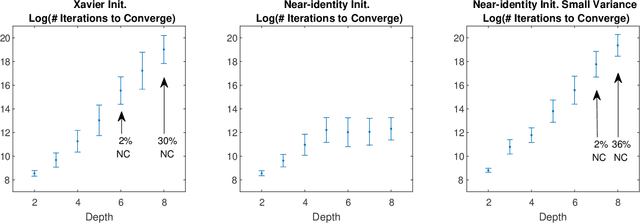
In this note, we study the dynamics of gradient descent on objective functions of the form $f(\prod_{i=1}^{k} w_i)$ (with respect to scalar parameters $w_1,\ldots,w_k$), which arise in the context of training depth-$k$ linear neural networks. We prove that for standard random initializations, and under mild assumptions on $f$, the number of iterations required for convergence scales exponentially with the depth $k$. This highlights a potential obstacle in understanding the convergence of gradient-based methods for deep linear neural networks, where $k$ is large.
* Comparison to previous version: Same results under weaker versions of
assumptions 3 and 4 (requiring minor changes in proofs); some typos fixed
View paper on