 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategorization of Comparative Sentences for Argument Mining
Paper and Code

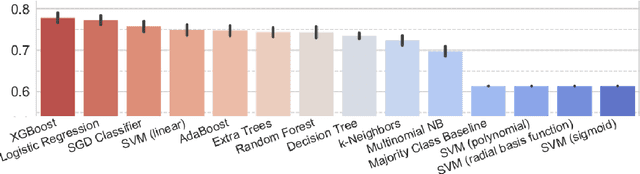
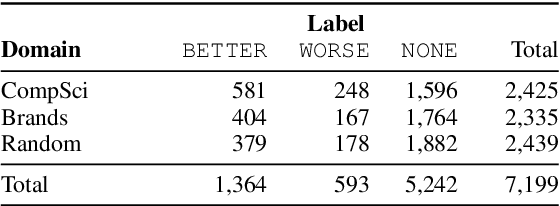
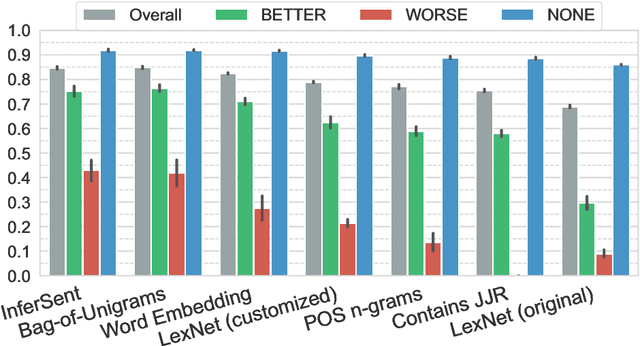
We present the first work on domain-independent comparative argument mining (CAM), which is the automatic extraction of direct comparisons from text. After motivating the need and identifying the widespread use of this so far under-researched topic, we present the first publicly available open-domain dataset for CAM. The dataset was collected using crowdsourcing and contains 7199 unique sentences for 217 distinct comparison target pairs selected over several domains, of which 27% contain a directed (better vs. worse) comparison. In classification experiments, we examine the impact of representations, features, and classifiers, and reach an F1-score of 88% with a gradient boosting model based on pre-trained sentence embeddings, especially reliably identifying non-comparative sentences. This paves the way for domain-independent comparison extraction from web-scale corpora for the use in result ranking and presentation for comparative queries.