 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGame-Based Video-Context Dialogue
Paper and Code
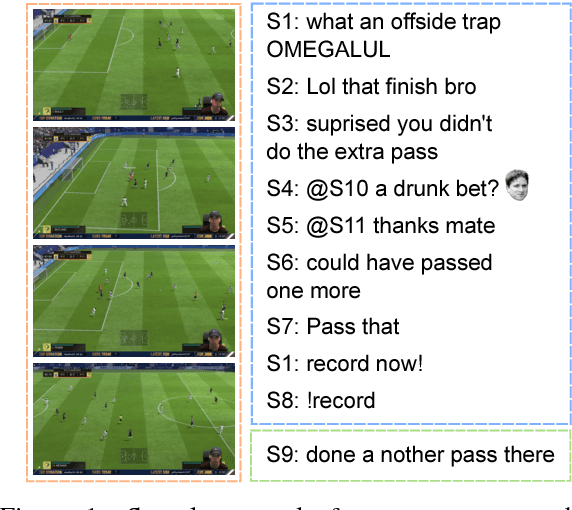

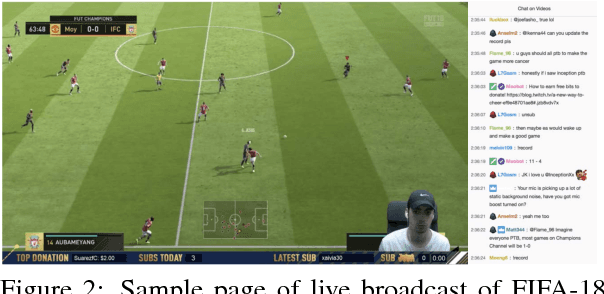
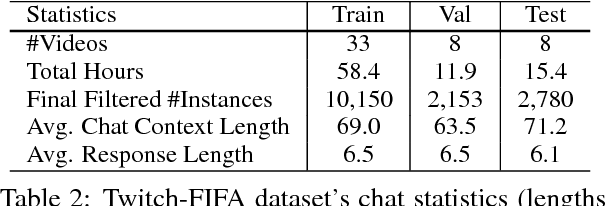
Current dialogue systems focus more on textual and speech context knowledge and are usually based on two speakers. Some recent work has investigated static image-based dialogue. However, several real-world human interactions also involve dynamic visual context (similar to videos) as well as dialogue exchanges among multiple speakers. To move closer towards such multimodal conversational skills and visually-situated applications, we introduce a new video-context, many-speaker dialogue dataset based on live-broadcast soccer game videos and chats from Twitch.tv. This challenging testbed allows us to develop visually-grounded dialogue models that should generate relevant temporal and spatial event language from the live video, while also being relevant to the chat history. For strong baselines, we also present several discriminative and generative models, e.g., based on tridirectional attention flow (TriDAF). We evaluate these models via retrieval ranking-recall, automatic phrase-matching metrics, as well as human evaluation studies. We also present dataset analyses, model ablations, and visualizations to understand the contribution of different modalities and model components.