 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Based Multi-modal Addressee Recognition in Visual Scenes with Utterances
Paper and Code
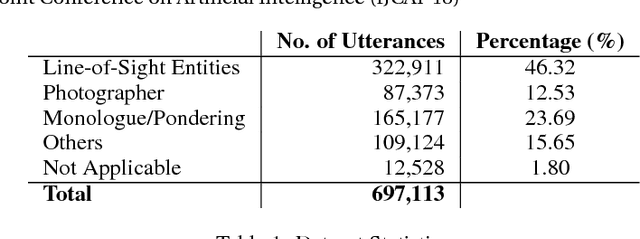

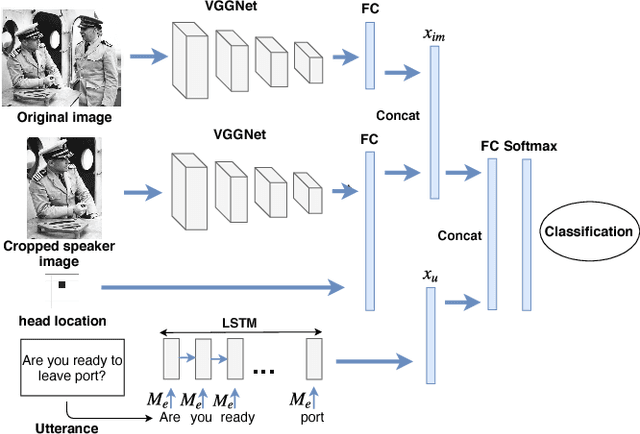
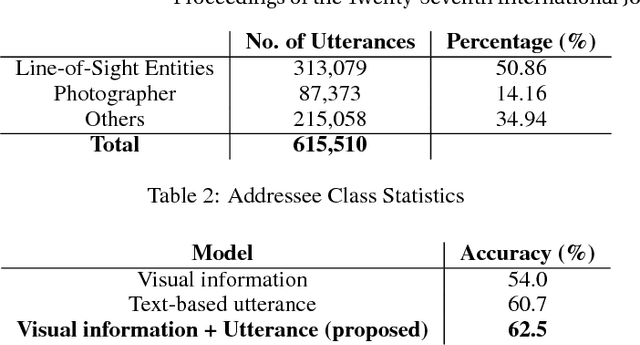
With the widespread use of intelligent systems, such as smart speakers, addressee recognition has become a concern in human-computer interaction, as more and more people expect such systems to understand complicated social scenes, including those outdoors, in cafeterias, and hospitals. Because previous studies typically focused only on pre-specified tasks with limited conversational situations such as controlling smart homes, we created a mock dataset called Addressee Recognition in Visual Scenes with Utterances (ARVSU) that contains a vast body of image variations in visual scenes with an annotated utterance and a corresponding addressee for each scenario. We also propose a multi-modal deep-learning-based model that takes different human cues, specifically eye gazes and transcripts of an utterance corpus, into account to predict the conversational addressee from a specific speaker's view in various real-life conversational scenarios. To the best of our knowledge, we are the first to introduce an end-to-end deep learning model that combines vision and transcripts of utterance for addressee recognition. As a result, our study suggests that future addressee recognition can reach the ability to understand human intention in many social situations previously unexplored, and our modality dataset is a first step in promoting research in this field.