Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Video Understanding
Paper and Code
Sep 04, 2018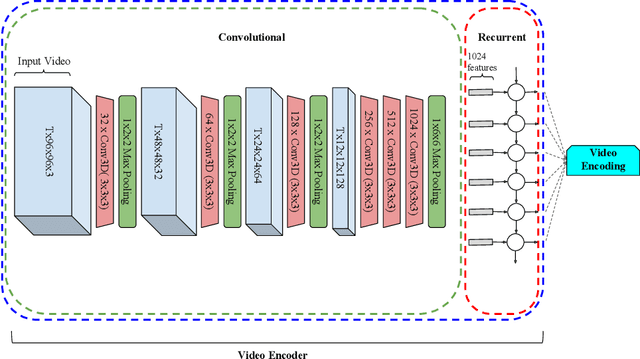
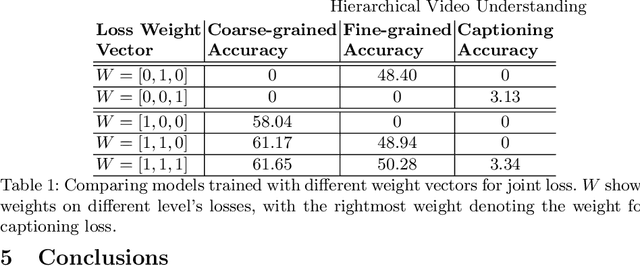
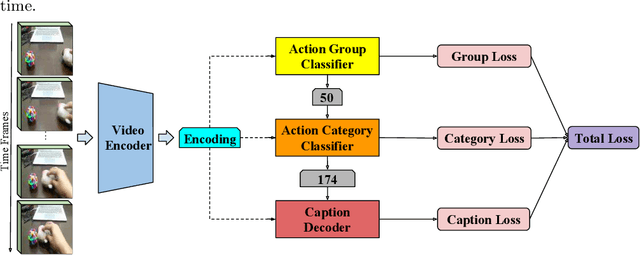

We introduce a hierarchical architecture for video understanding that exploits the structure of real world actions by capturing targets at different levels of granularity. We design the model such that it first learns simpler coarse-grained tasks, and then moves on to learn more fine-grained targets. The model is trained with a joint loss on different granularity levels. We demonstrate empirical results on the recent release of Something-Something dataset, which provides a hierarchy of targets, namely coarse-grained action groups, fine-grained action categories, and captions. Experiments suggest that models that exploit targets at different levels of granularity achieve better performance on all levels.
View paper on