 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Spectrogram Inversion using Multi-head Convolutional Neural Networks
Paper and Code
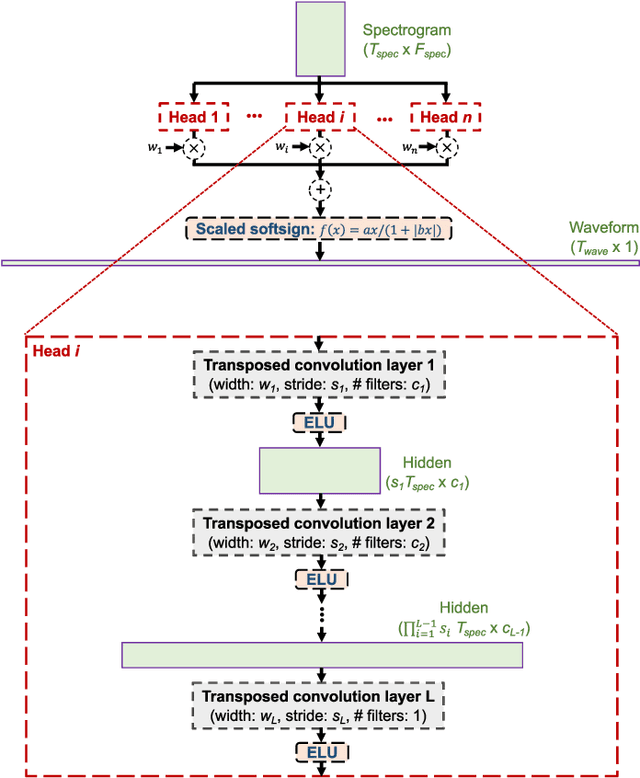
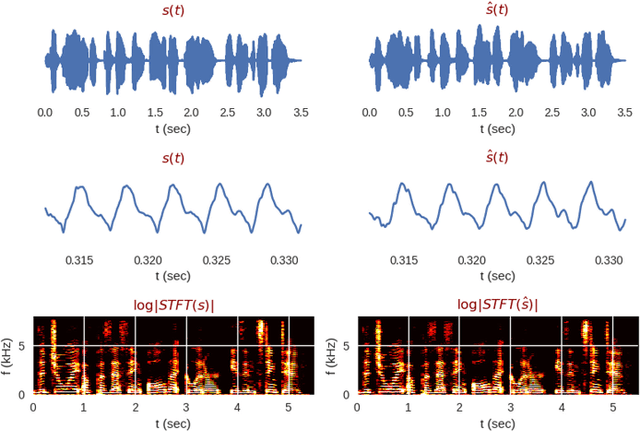
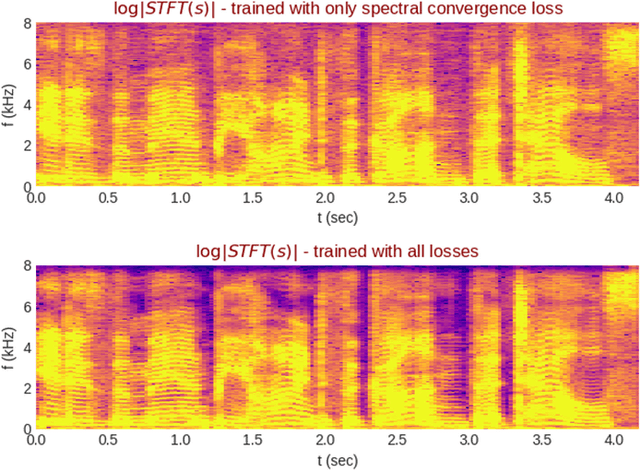
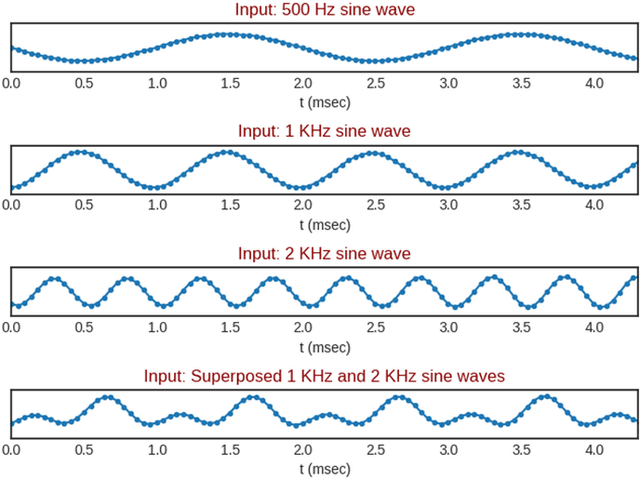
We propose the multi-head convolutional neural network (MCNN) architecture for waveform synthesis from spectrograms. Nonlinear interpolation in MCNN is employed with transposed convolution layers in parallel heads. MCNN achieves more than an order of magnitude higher compute intensity than commonly-used iterative algorithms like Griffin-Lim, yielding efficient utilization for modern multi-core processors, and very fast (more than 300x real-time) waveform synthesis. For training of MCNN, we use a large-scale speech recognition dataset and losses defined on waveforms that are related to perceptual audio quality. We demonstrate that MCNN constitutes a very promising approach for high-quality speech synthesis, without any iterative algorithms or autoregression in computations.