 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Language Modeling by Decoding the Past
Paper and Code
Sep 29, 2018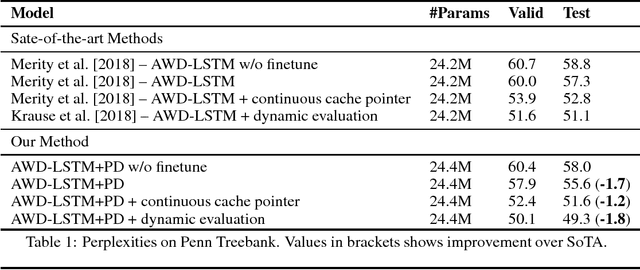
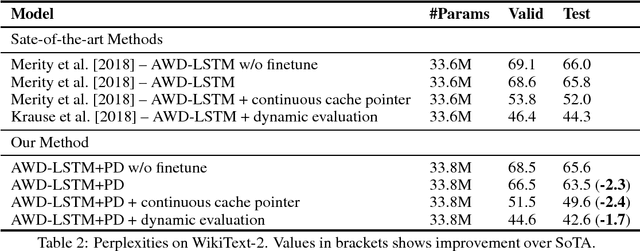
Highly regularized LSTMs achieve impressive results on several benchmark datasets in language modeling. We propose a new regularization method based on decoding the last token in the context using the predicted distribution of the next token. This biases the model towards retaining more contextual information, in turn improving its ability to predict the next token. With negligible overhead in the number of parameters and training time, our past decode regularization (PDR) method achieves state-of-the-art word level perplexity on the Penn Treebank (55.6) and WikiText-2 (63.5) datasets and bits-per-character on the Penn Treebank Character (1.169) dataset for character level language modeling. Using dynamic evaluation, we also achieve the first sub 50 perplexity of 49.3 on the Penn Treebank test set.