Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Sentence Representations Using Sequence Consistency
Paper and Code
Sep 29, 2018
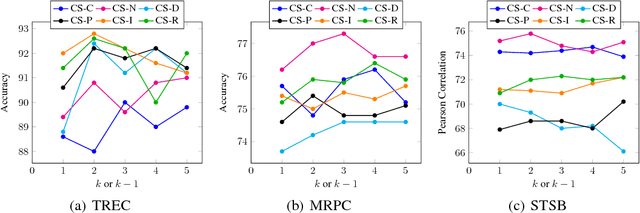
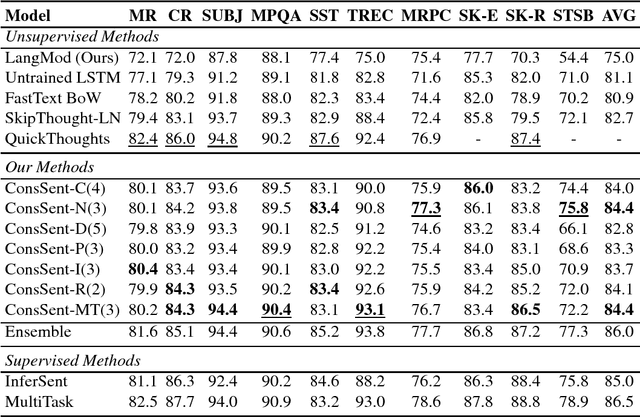
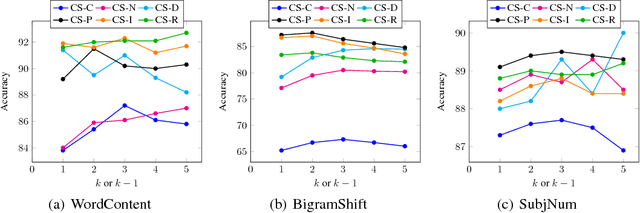
Computing universal distributed representations of sentences is a fundamental task in natural language processing. We propose a simple, yet surprisingly powerful unsupervised method to learn such representations by enforcing consistency constraints on sequences of tokens. We consider two classes of such constraints - sequences that form a sentence and between two sequences that form a sentence when merged. We learn a sentence encoder by training it to distinguish between consistent and inconsistent examples. Extensive evaluation on several transfer learning and linguistic probing tasks shows improved performance over strong unsupervised and supervised baselines, substantially surpassing them in several cases.
* Submitted to ICLR 2019
View paper on