 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective optimization to explicitly account for model complexity when learning Bayesian Networks
Paper and Code
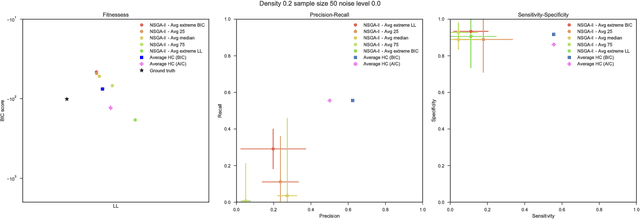
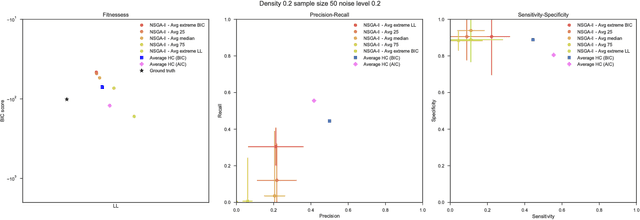
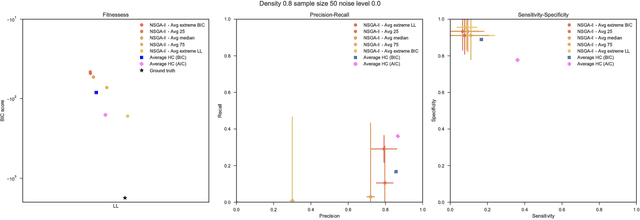
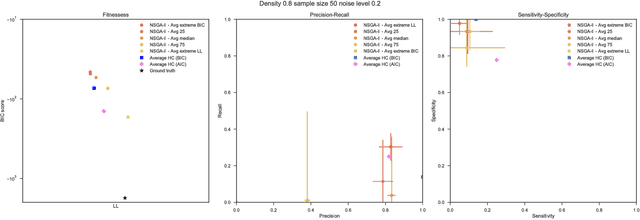
Bayesian Networks have been widely used in the last decades in many fields, to describe statistical dependencies among random variables. In general, learning the structure of such models is a problem with considerable theoretical interest that still poses many challenges. On the one hand, this is a well-known NP-complete problem, which is practically hardened by the huge search space of possible solutions. On the other hand, the phenomenon of I-equivalence, i.e., different graphical structures underpinning the same set of statistical dependencies, may lead to multimodal fitness landscapes further hindering maximum likelihood approaches to solve the task. Despite all these difficulties, greedy search methods based on a likelihood score coupled with a regularization term to account for model complexity, have been shown to be surprisingly effective in practice. In this paper, we consider the formulation of the task of learning the structure of Bayesian Networks as an optimization problem based on a likelihood score. Nevertheless, our approach do not adjust this score by means of any of the complexity terms proposed in the literature; instead, it accounts directly for the complexity of the discovered solutions by exploiting a multi-objective optimization procedure. To this extent, we adopt NSGA-II and define the first objective function to be the likelihood of a solution and the second to be the number of selected arcs. We thoroughly analyze the behavior of our method on a wide set of simulated data, and we discuss the performance considering the goodness of the inferred solutions both in terms of their objective functions and with respect to the retrieved structure. Our results show that NSGA-II can converge to solutions characterized by better likelihood and less arcs than classic approaches, although paradoxically frequently characterized by a lower similarity to the target network.