 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubly Attentive Transformer Machine Translation
Paper and Code
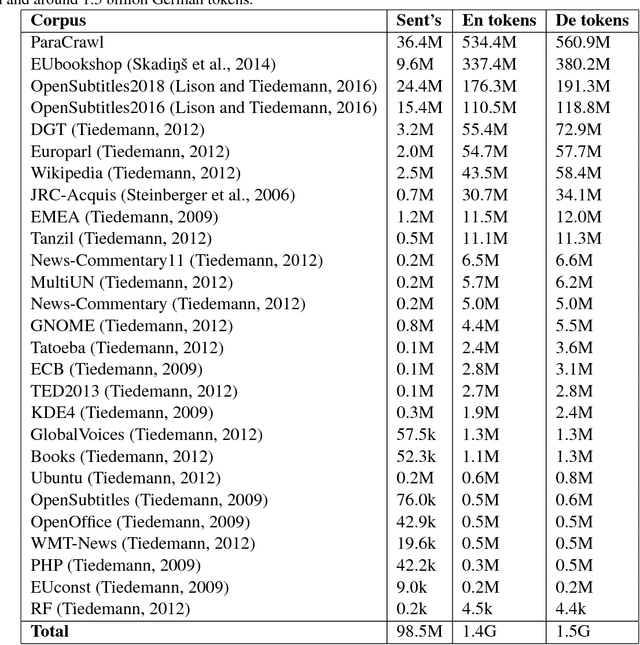
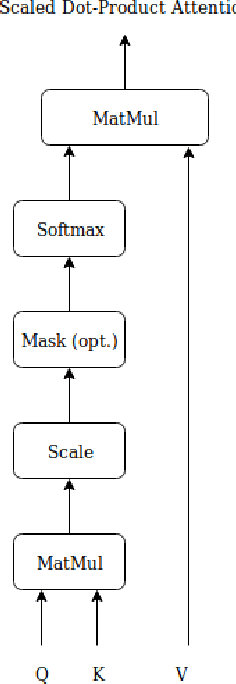
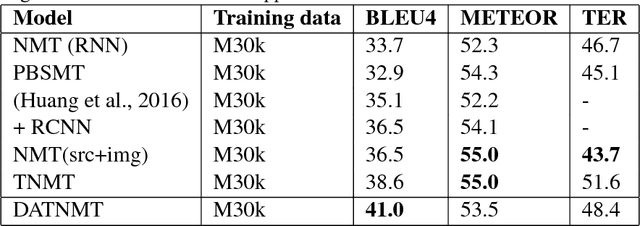
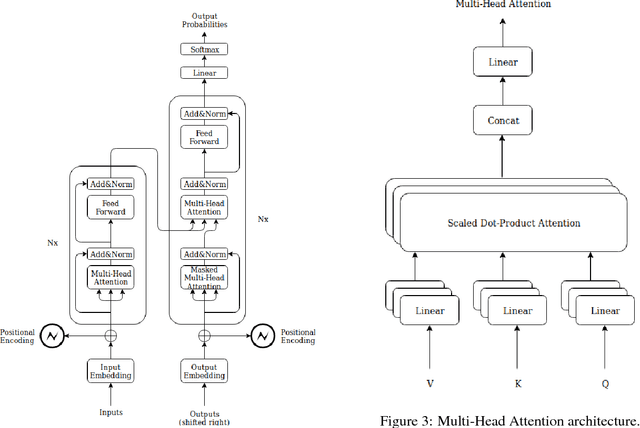
In this paper a doubly attentive transformer machine translation model (DATNMT) is presented in which a doubly-attentive transformer decoder normally joins spatial visual features obtained via pretrained convolutional neural networks, conquering any gap between image captioning and translation. In this framework, the transformer decoder figures out how to take care of source-language words and parts of an image freely by methods for two separate attention components in an Enhanced Multi-Head Attention Layer of doubly attentive transformer, as it generates words in the target language. We find that the proposed model can effectively exploit not just the scarce multimodal machine translation data, but also large general-domain text-only machine translation corpora, or image-text image captioning corpora. The experimental results show that the proposed doubly-attentive transformer-decoder performs better than a single-decoder transformer model, and gives the state-of-the-art results in the English-German multimodal machine translation task.