 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffectiveness of Scaled Exponentially-Regularized Linear Units (SERLUs)
Paper and Code
Jul 27, 2018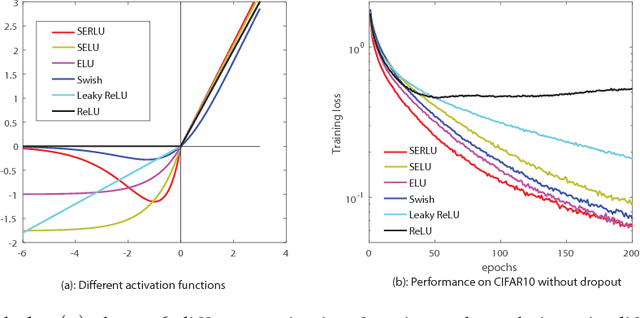
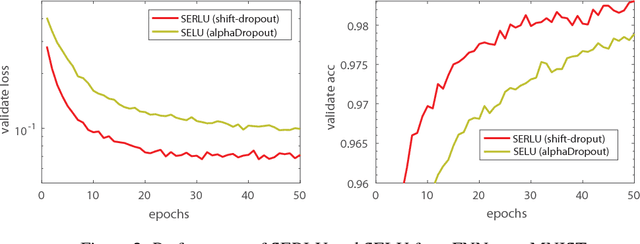

Recently, self-normalizing neural networks (SNNs) have been proposed with the intention to avoid batch or weight normalization. The key step in SNNs is to properly scale the exponential linear unit (referred to as SELU) to inherently incorporate normalization based on central limit theory. SELU is a monotonically increasing function, where it has an approximately constant negative output for large negative input. In this work, we propose a new activation function to break the monotonicity property of SELU while still preserving the self-normalizing property. Differently from SELU, the new function introduces a bump-shaped function in the region of negative input by regularizing a linear function with a scaled exponential function, which is referred to as a scaled exponentially-regularized linear unit (SERLU). The bump-shaped function has approximately zero response to large negative input while being able to push the output of SERLU towards zero mean statistically. To effectively combat over-fitting, we develop a so-called shift-dropout for SERLU, which includes standard dropout as a special case. Experimental results on MNIST, CIFAR10 and CIFAR100 show that SERLU-based neural networks provide consistently promising results in comparison to other 5 activation functions including ELU, SELU, Swish, Leakly ReLU and ReLU.