 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEBIC: an open source software for high-dimensional and big data biclustering analyses
Paper and Code
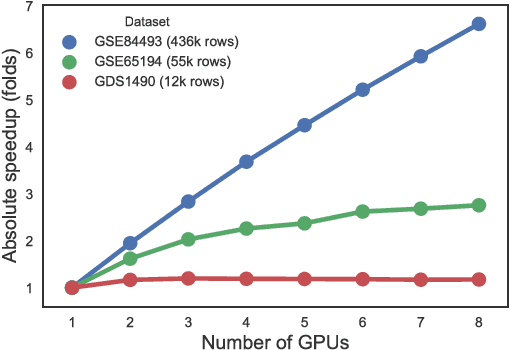

Motivation: In this paper we present the latest release of EBIC, a next-generation biclustering algorithm for mining genetic data. The major contribution of this paper is adding support for big data, making it possible to efficiently run large genomic data mining analyses. Additional enhancements include integration with R and Bioconductor and an option to remove influence of missing value on the final result. Results: EBIC was applied to datasets of different sizes, including a large DNA methylation dataset with 436,444 rows. For the largest dataset we observed over 6.6 fold speedup in computation time on a cluster of 8 GPUs compared to running the method on a single GPU. This proves high scalability of the algorithm. Availability: The latest version of EBIC could be downloaded from http://github.com/EpistasisLab/ebic . Installation and usage instructions are also available online.