 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgesignProx: One-Bit Proximal Algorithm for Nonconvex Stochastic Optimization
Paper and Code
Oct 23, 2018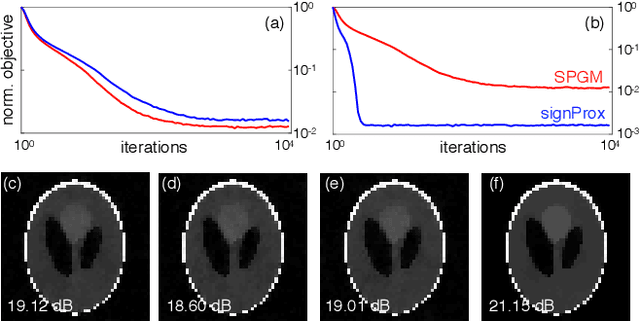
Stochastic gradient descent (SGD) is one of the most widely used optimization methods for parallel and distributed processing of large datasets. One of the key limitations of distributed SGD is the need to regularly communicate the gradients between different computation nodes. To reduce this communication bottleneck, recent work has considered a one-bit variant of SGD, where only the sign of each gradient element is used in optimization. In this paper, we extend this idea by proposing a stochastic variant of the proximal-gradient method that also uses one-bit per update element. We prove the theoretical convergence of the method for non-convex optimization under a set of explicit assumptions. Our results indicate that the compressed method can match the convergence rate of the uncompressed one, making the proposed method potentially appealing for distributed processing of large datasets.