 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeSTNet: Densely Fused Spatial Transformer Networks
Paper and Code
Jul 16, 2018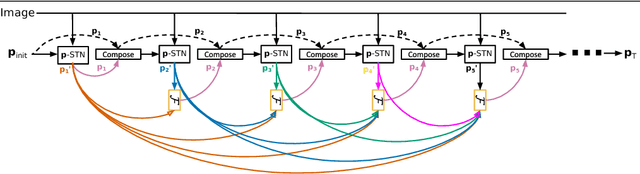

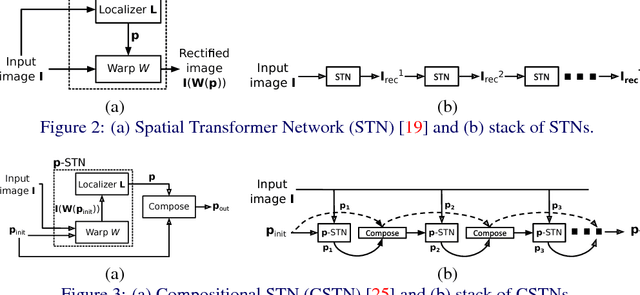

Modern Convolutional Neural Networks (CNN) are extremely powerful on a range of computer vision tasks. However, their performance may degrade when the data is characterised by large intra-class variability caused by spatial transformations. The Spatial Transformer Network (STN) is currently the method of choice for providing CNNs the ability to remove those transformations and improve performance in an end-to-end learning framework. In this paper, we propose Densely Fused Spatial Transformer Network (DeSTNet), which, to our best knowledge, is the first dense fusion pattern for combining multiple STNs. Specifically, we show how changing the connectivity pattern of multiple STNs from sequential to dense leads to more powerful alignment modules. Extensive experiments on three benchmarks namely, MNIST, GTSRB, and IDocDB show that the proposed technique outperforms related state-of-the-art methods (i.e., STNs and CSTNs) both in terms of accuracy and robustness.