 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelayed Bandit Online Learning with Unknown Delays
Paper and Code
Jul 09, 2018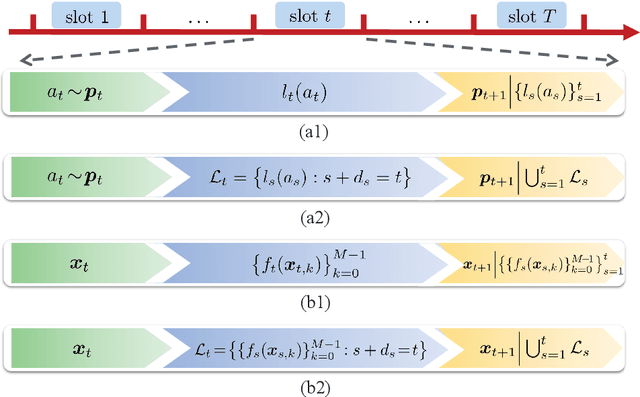
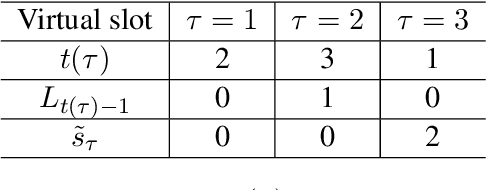
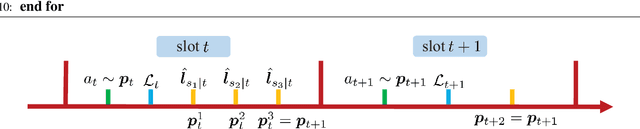

This paper studies bandit learning problems with delayed feedback, which included multi-armed bandit (MAB) and bandit convex optimization (BCO). Given only function value information (a.k.a. bandit feedback), algorithms for both MAB and BCO typically rely on (possibly randomized) gradient estimators based on function values, and then feed them into well-studied gradient-based algorithms. Different from existing works however, the setting considered here is more challenging, where the bandit feedback is not only delayed but also the presence of its delay is not revealed to the learner. Existing algorithms for delayed MAB and BCO become intractable in this setting. To tackle such challenging settings, DEXP3 and DBGD have been developed for MAB and BCO, respectively. Leveraging a unified analysis framework, it is established that both DEXP3 and DBGD guarantee an ${\cal O}\big( \sqrt{T+D} \big)$ regret over $T$ time slots with $D$ being the overall delay accumulated over slots. The new regret bounds match those in full information settings.