 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the semantic structure of text documents using paragraph-aware Topic Models
Paper and Code
Jun 26, 2018
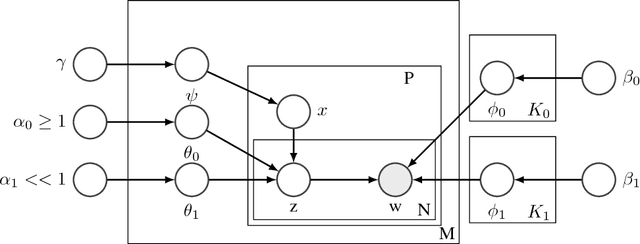
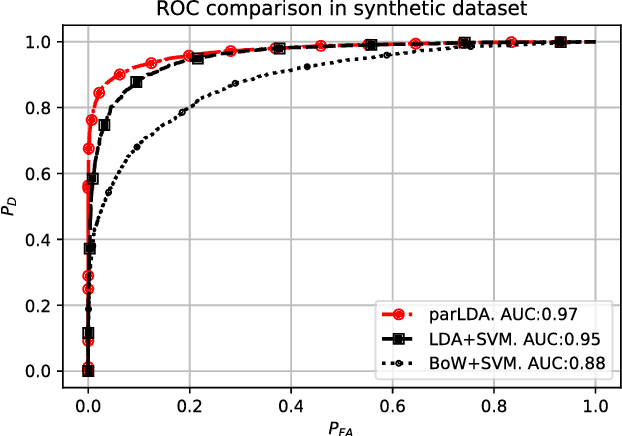

Classic Topic Models are built under the Bag Of Words assumption, in which word position is ignored for simplicity. Besides, symmetric priors are typically used in most applications. In order to easily learn topics with different properties among the same corpus, we propose a new line of work in which the paragraph structure is exploited. Our proposal is based on the following assumption: in many text document corpora there are formal constraints shared across all the collection, e.g. sections. When this assumption is satisfied, some paragraphs may be related to general concepts shared by all documents in the corpus, while others would contain the genuine description of documents. Assuming each paragraph can be semantically more general, specific, or hybrid, we look for ways to measure this, transferring this distinction to topics and being able to learn what we call specific and general topics. Experiments show that this is a proper methodology to highlight certain paragraphs in structured documents at the same time we learn interesting and more diverse topics.