Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Machine Translation for Low Resource Languages using Bilingual Lexicon Induced from Comparable Corpora
Paper and Code
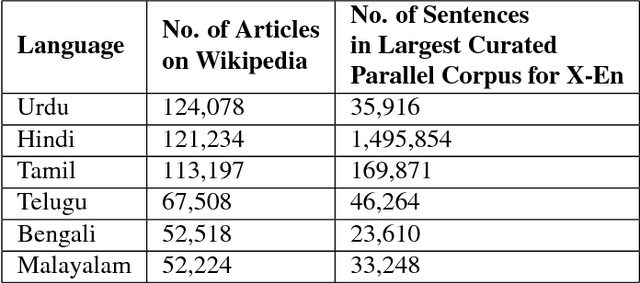
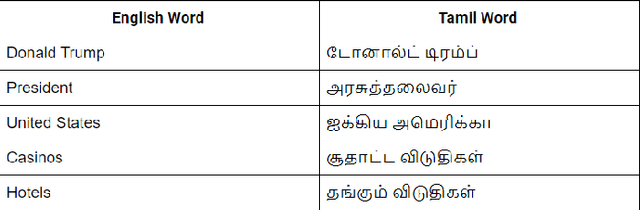
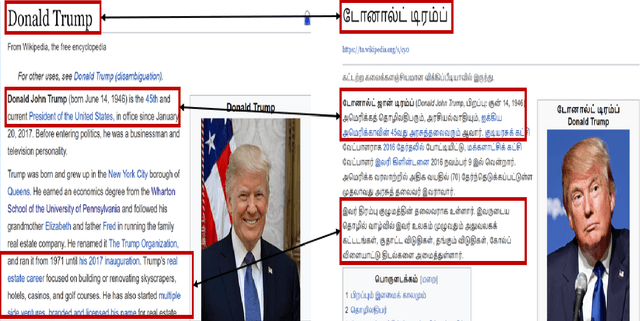
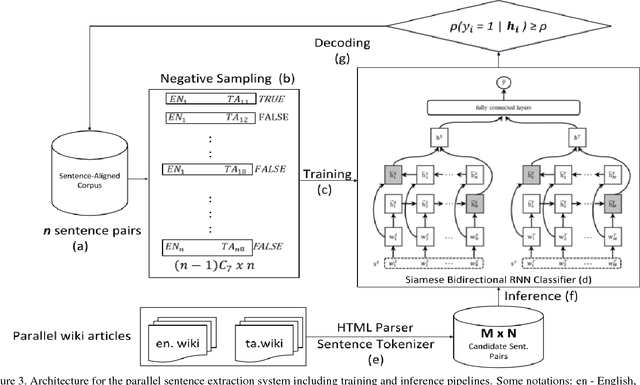
Resources for the non-English languages are scarce and this paper addresses this problem in the context of machine translation, by automatically extracting parallel sentence pairs from the multilingual articles available on the Internet. In this paper, we have used an end-to-end Siamese bidirectional recurrent neural network to generate parallel sentences from comparable multilingual articles in Wikipedia. Subsequently, we have showed that using the harvested dataset improved BLEU scores on both NMT and phrase-based SMT systems for the low-resource language pairs: English--Hindi and English--Tamil, when compared to training exclusively on the limited bilingual corpora collected for these language pairs.
* 8 pages, 3 figures, 4 tables, NAACL-SRW (2018)
View paper on