 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Language Identification for Romance Languages using Stop Words and Diacritics
Paper and Code
Jun 14, 2018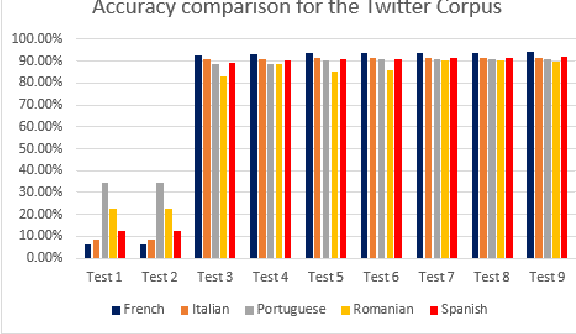

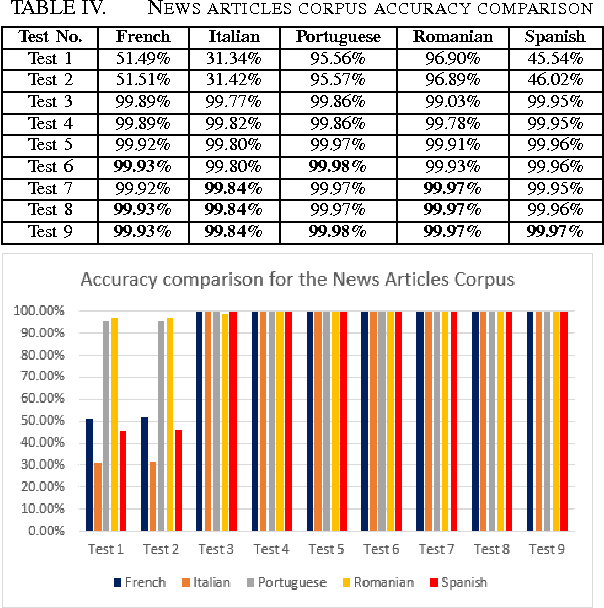
Automatic language identification is a natural language processing problem that tries to determine the natural language of a given content. In this paper we present a statistical method for automatic language identification of written text using dictionaries containing stop words and diacritics. We propose different approaches that combine the two dictionaries to accurately determine the language of textual corpora. This method was chosen because stop words and diacritics are very specific to a language, although some languages have some similar words and special characters they are not all common. The languages taken into account were romance languages because they are very similar and usually it is hard to distinguish between them from a computational point of view. We have tested our method using a Twitter corpus and a news article corpus. Both corpora consists of UTF-8 encoded text, so the diacritics could be taken into account, in the case that the text has no diacritics only the stop words are used to determine the language of the text. The experimental results show that the proposed method has an accuracy of over 90% for small texts and over 99.8% for