 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Policy Reuse
Paper and Code
Jun 28, 2018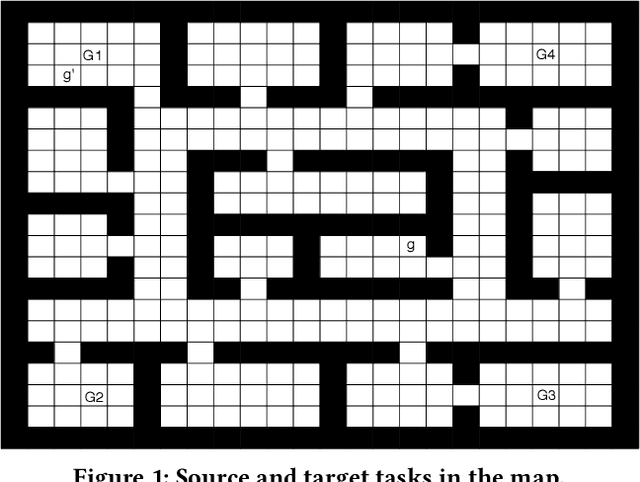
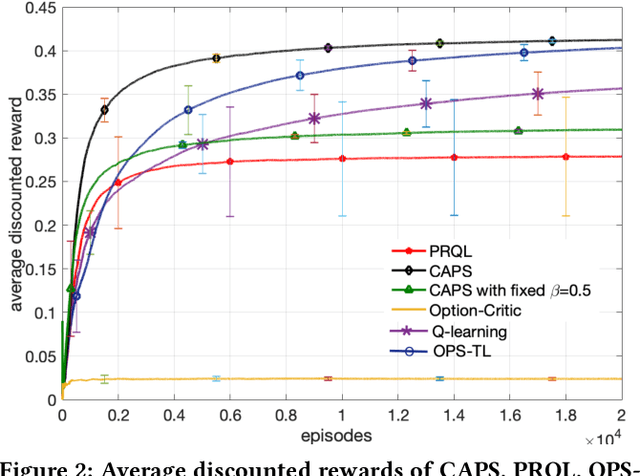
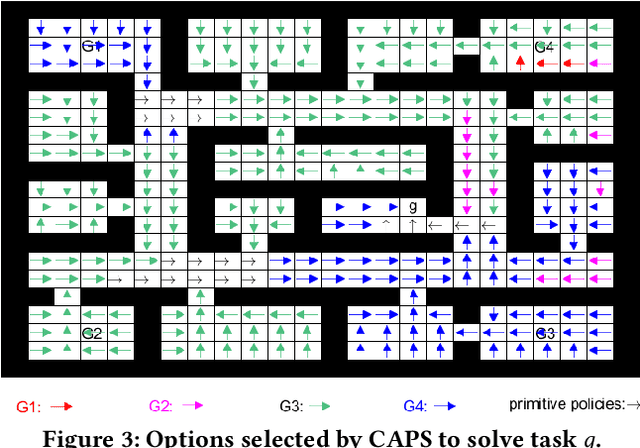
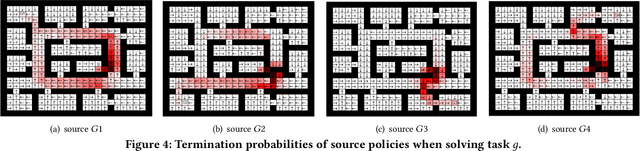
Transfer learning can greatly speed up reinforcement learning for a new task by leveraging policies of relevant tasks. Existing works of policy reuse either focus on only selecting a single best source policy for transfer without considering contexts, or cannot guarantee to learn an optimal policy for a target task. To improve transfer efficiency and guarantee optimality, we develop a novel policy reuse method, called Context-Aware Policy reuSe (CAPS), that enables multi-policy transfer. Our method learns when and which source policy is best for reuse, as well as when to terminate its reuse. CAPS provides theoretical guarantees in convergence and optimality for both source policy selection and target task learning. Empirical results on a grid-based navigation domain and the Pygame Learning Environment demonstrate that CAPS significantly outperforms other state-of-the-art policy reuse methods.