 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining LSTM Networks with Resistive Cross-Point Devices
Paper and Code
Jun 01, 2018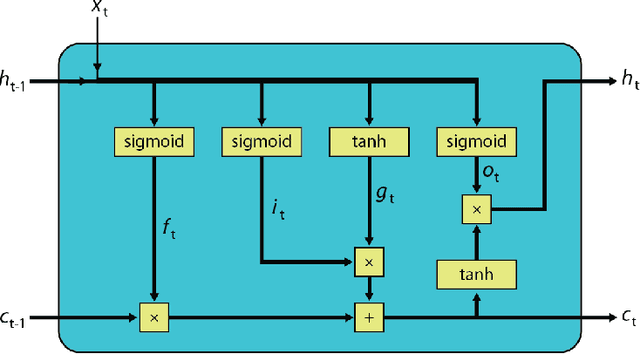
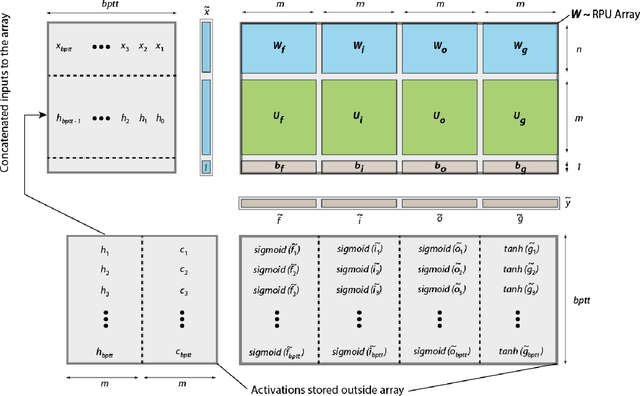
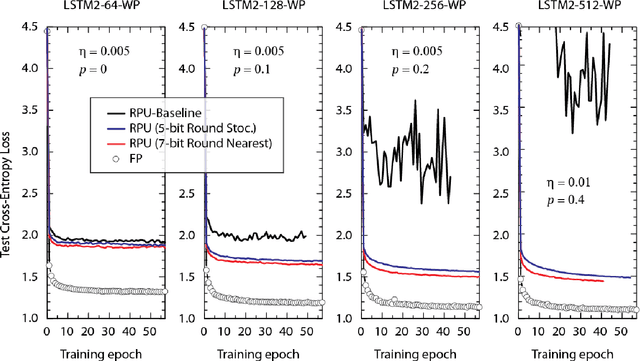
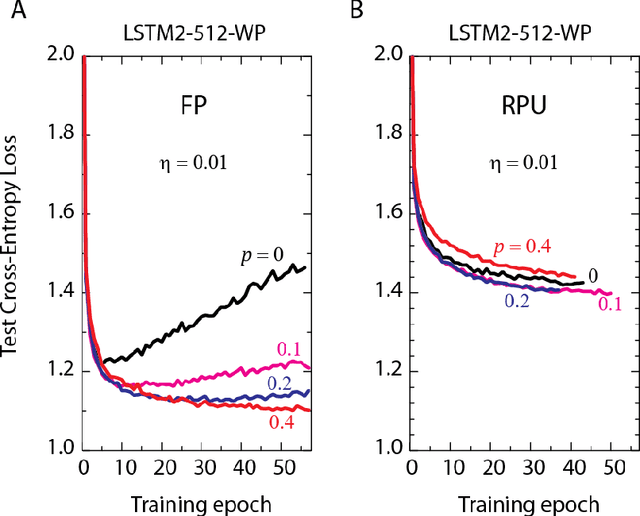
In our previous work we have shown that resistive cross point devices, so called Resistive Processing Unit (RPU) devices, can provide significant power and speed benefits when training deep fully connected networks as well as convolutional neural networks. In this work, we further extend the RPU concept for training recurrent neural networks (RNNs) namely LSTMs. We show that the mapping of recurrent layers is very similar to the mapping of fully connected layers and therefore the RPU concept can potentially provide large acceleration factors for RNNs as well. In addition, we study the effect of various device imperfections and system parameters on training performance. Symmetry of updates becomes even more crucial for RNNs; already a few percent asymmetry results in an increase in the test error compared to the ideal case trained with floating point numbers. Furthermore, the input signal resolution to device arrays needs to be at least 7 bits for successful training. However, we show that a stochastic rounding scheme can reduce the input signal resolution back to 5 bits. Further, we find that RPU device variations and hardware noise are enough to mitigate overfitting, so that there is less need for using dropout. We note that the models trained here are roughly 1500 times larger than the fully connected network trained on MNIST dataset in terms of the total number of multiplication and summation operations performed per epoch. Thus, here we attempt to study the validity of the RPU approach for large scale networks.