 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResisting Adversarial Attacks using Gaussian Mixture Variational Autoencoders
Paper and Code
May 31, 2018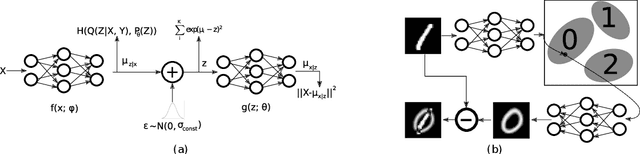
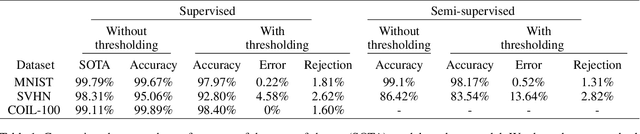


Susceptibility of deep neural networks to adversarial attacks poses a major theoretical and practical challenge. All efforts to harden classifiers against such attacks have seen limited success. Two distinct categories of samples to which deep networks are vulnerable, "adversarial samples" and "fooling samples", have been tackled separately so far due to the difficulty posed when considered together. In this work, we show how one can address them both under one unified framework. We tie a discriminative model with a generative model, rendering the adversarial objective to entail a conflict. Our model has the form of a variational autoencoder, with a Gaussian mixture prior on the latent vector. Each mixture component of the prior distribution corresponds to one of the classes in the data. This enables us to perform selective classification, leading to the rejection of adversarial samples instead of misclassification. Our method inherently provides a way of learning a selective classifier in a semi-supervised scenario as well, which can resist adversarial attacks. We also show how one can reclassify the rejected adversarial samples.