 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Corpus of English-Hindi Code-Mixed Tweets for Sarcasm Detection
Paper and Code
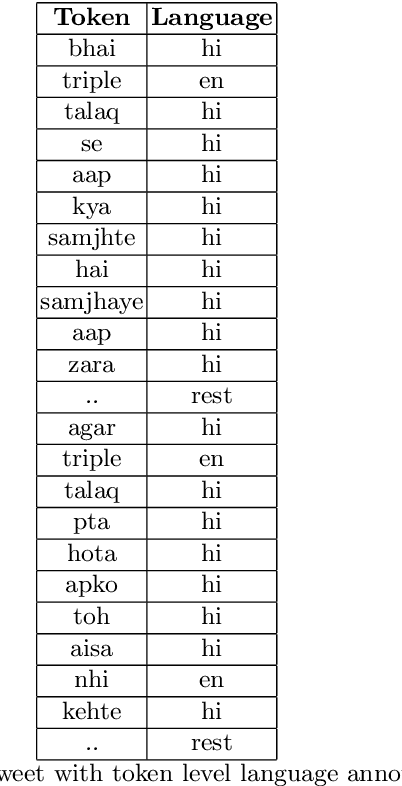

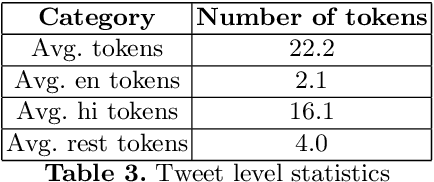
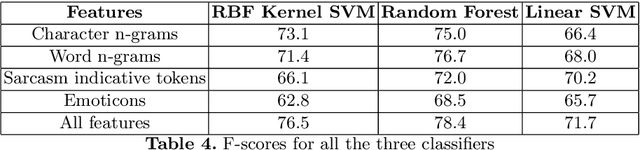
Social media platforms like twitter and facebook have be- come two of the largest mediums used by people to express their views to- wards different topics. Generation of such large user data has made NLP tasks like sentiment analysis and opinion mining much more important. Using sarcasm in texts on social media has become a popular trend lately. Using sarcasm reverses the meaning and polarity of what is implied by the text which poses challenge for many NLP tasks. The task of sarcasm detection in text is gaining more and more importance for both commer- cial and security services. We present the first English-Hindi code-mixed dataset of tweets marked for presence of sarcasm and irony where each token is also annotated with a language tag. We present a baseline su- pervised classification system developed using the same dataset which achieves an average F-score of 78.4 after using random forest classifier and performing 10-fold cross validation.