Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Evaluations of Continual Learning
Paper and Code
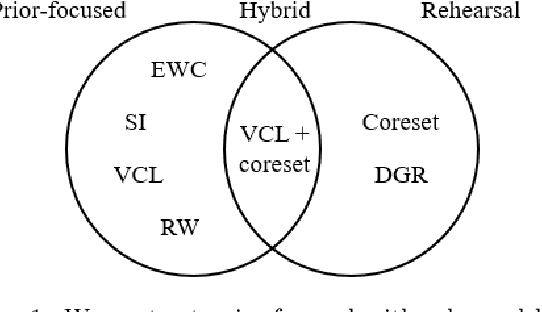

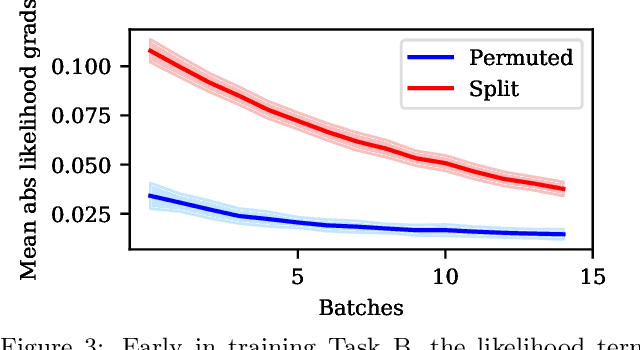
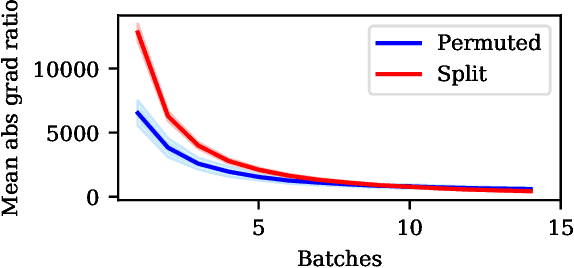
The experiments used in current continual learning research do not faithfully assess fundamental challenges of learning continually. We examine standard evaluations and show why these evaluations make some types of continual learning approaches look better than they are. In particular, current evaluations are biased towards continual learning approaches that treat previous models as a prior (e.g., EWC, VCL). We introduce desiderata for continual learning evaluations and explain why their absence creates misleading comparisons. Our analysis calls for a reprioritization of research effort by the community.
View paper on